
对快速实时 GPU 图像模糊算法的调查
0/5 (0投票)
在这篇博客文章中,我将开始探讨模糊滤镜这个主题。
引言
英特尔®开发者专区提供跨平台应用开发的工具和操作指南、平台和技术信息、代码示例以及同行专业知识,帮助开发者创新并取得成功。加入我们的Android、物联网、英特尔®实感™技术和Windows社区,下载工具,获取开发套件,与志同道合的开发者分享想法,并参与编程马拉松、竞赛、路演和当地活动。
在这篇博客文章中,我将开始探讨模糊滤镜这个主题。我最初的打算是……
- 提供几种流行的实时图像模糊滤镜的概述和优化思路,适用于范围非常广的硬件(从低于4W的移动设备GPU到高端250W+的桌面GPU)。
- 提供一个在Windows桌面OpenGL和Android OpenGL ES 3.0和3.1上运行的技术示例,包括在OpenGL ES 3.1上使用计算着色器。
……但我意识到,要彻底探讨这个主题可能需要不止一篇博客文章(以及更多的工作),所以下面是第一部分。因此,请随时在底部的评论区贡献您的想法和更正。
图像模糊滤镜
图像模糊滤镜在计算机图形学中普遍使用——无论是景深或HDR泛光的重要组成部分,还是其他后处理效果,模糊滤镜存在于大多数3D游戏引擎中,并且通常存在于多个地方。模糊图像是相当微不足道的事情:只需收集相邻像素,将它们平均,然后您就得到了新值,对吗?

是的,但有不同的实现方式,会产生不同的视觉效果、质量和性能。
本文主要关注性能(和质量权衡),因为天真解法和更优化解法之间的成本差异有时可能是一个数量级,而且不同的算法在不同硬件上可能更优化。
我将探讨并对比三种最常见的技术,以及它们在移动GPU到集成显卡和独立显卡等一系列现代GPU硬件中的表现。如果您正在使用更好或不同的方法,请随时评论——我很乐意将其添加到示例中进行性能分析和测试,并在下次更新中提供。
这三种算法是
- 使用高斯分布的经典卷积模糊
- Kawase Bloom的泛化——由Masaki Kawase在其GDC2003演讲《DOUBLE-S.T.E.A.L (Wreckless) 中的帧缓冲区后处理效果》中提出的一个古老但仍然非常适用的滤镜
- 一种受Fabian "ryg" Giesen文章启发而基于计算着色器的移动平均算法:http://fgiesen.wordpress.com/2012/07/30/fast-blurs-1/ 和 http://fgiesen.wordpress.com/2012/08/01/fast-blurs-2/。
它们都是通用算法,完全适用于泛光HDR滤镜等效果。然而,在特定场景中,例如用于景深,它们将需要额外的定制(例如加权采样以避免光晕/溢出),这可能会影响相对性能。要实现类似中值滤镜(http://en.wikipedia.org/wiki/Median_filter)的效果,还需要更多的修改。然而,这里介绍的优化技术和数据即使您打算进行特殊模糊,如散景(http://en.wikipedia.org/wiki/Bokeh)、艾里斑(http://en.wikipedia.org/wiki/Airy_disk)或各种图像空间镜头光晕效果,也应该有所帮助。该示例还提供实时图表可视化,可用于分析任何自定义模糊技术。

还应注意的是,尽管通用算法更容易理解、实现、重用和维护,但在某些情况下,专用算法可能做得更好。一个这样的例子(尽管我没有将其与此处介绍的算法进行比较)在此处介绍:http://software.intel.com/en-us/articles/compute-shader-hdr-and-bloom(基于“HDR:Bungie之道。微软Gamefest 2006。”)。
2D高斯模糊滤镜
让我们从“高斯模糊滤镜”开始,这是一种广泛使用的滤镜,用于减少图像细节和噪点(例如,模拟镜头失焦模糊)。它被称为高斯模糊,因为图像是使用高斯曲线模糊的(http://en.wikipedia.org/wiki/Gaussian_function)。

朴素实现
高斯模糊的常用方法是使用卷积核(http://en.wikipedia.org/wiki/Kernel_(image_processing)#Convolution)。这仅仅意味着我们构建一个2D矩阵的归一化预计算高斯函数值并将它们用作权重,然后对所有相邻像素进行加权求和,以计算每个像素的新(过滤后)值。

对于2D滤镜,这也意味着要计算每个像素,我们必须进行一个核大小的双重循环,因此每个像素的算法复杂度变为 **O( n^2 )**(其中n是核的高度和/或宽度,因为它们相同)。除了最小的核大小,这很快变得非常昂贵。
可分离的水平/垂直
幸运的是,2D高斯滤镜核是可分离的,因为它可以表示为两个向量的外积(参见http://blogs.mathworks.com/steve/2006/10/04/separable-convolution/和http://blogs.mathworks.com/steve/2006/11/28/separable-convolution-part-2/),这意味着滤镜可以分成两个通道,水平和垂直,每个通道每个像素的复杂度为 **O( n )**(其中n是核大小)。这大大降低了计算成本,同时提供了完全相同的结果。

值得注意的是,在此阶段,相同的算法可用于任何其他适用的卷积(有关更多详细信息,请参阅上面的链接),例如某些锐化滤镜或边缘检测(如Sobel滤镜)。
使用GPU固定功能采样的更好可分离实现
到目前为止,我们忽略了实际的硬件实现,但是当我们将此算法应用于现实场景时,高斯模糊滤镜通道需要实时发生,通常在1280x720或更多像素的图像上。现代GPU(在移动和桌面设备上)都考虑到这一点,因此它们可以在几毫秒内完成也就不足为奇了——然而,节省其中的几毫秒仍然可能意味着游戏以次优的25帧或流畅的30帧每秒运行之间的差异。
算法上优越得多,这个可分离滤镜可以作为GPU着色器以高度并行的方式在GPU执行单元上运行,执行图像读取、数学运算和写入。
水平可分离高斯7x7滤镜通道的着色器伪代码
color = vec3( 0, 0, 0 );
for( int i = 0; i < 7; i++ )
{
color += textureLoad( texCoordCenter + vec2( i, 0 ) ) * SeparableGaussWeights[p];
}
return color;
然而,如http://rastergrid.com/blog/2010/09/efficient-gaussian-blur-with-linear-sampling/中详述的,我们可以利用固定功能的GPU硬件,即采样器,它可以加载两个(在我们的例子中)相邻的像素值,并根据提供的纹理坐标值返回一个插值结果,所有这些的成本大约等于一次纹理读取。这大约将着色器指令数量减半(将采样指令数量减半,并略微增加算术指令数量),并且可以将性能提高一倍(或者更少,如果受内存带宽限制)。
为此,我们必须计算一组新的权重和采样偏移量,使得当使用线性滤镜采样两个相邻像素时,我们得到它们之间的插值平均值,该平均值与其原始高斯可分离滤镜权重成正确比例。然后,我们使用新的权重集将所有采样加起来,最终得到的滤镜比我们最初的非优化朴素实现更快,但质量相同。
用于对7x7滤镜进行可分离水平或垂直通道的示例中的实际GLSL代码
// automatically generated by GenerateGaussFunctionCode in GaussianBlur.h
vec3 GaussianBlur( sampler2D tex0, vec2 centreUV, vec2 halfPixelOffset, vec2 pixelOffset )
{
vec3 colOut = vec3( 0, 0, 0 );
////////////////////////////////////////////////;
// Kernel width 7 x 7
//
const int stepCount = 2;
//
const float gWeights[stepCount] ={
0.44908,
0.05092
};
const float gOffsets[stepCount] ={
0.53805,
2.06278
};
////////////////////////////////////////////////;
for( int i = 0; i < stepCount; i++ )
{
vec2 texCoordOffset = gOffsets[i] * pixelOffset;
vec3 col = texture( tex0, centreUV + texCoordOffset ).xyz +
texture( tex0, centreUV – texCoordOffset ).xyz;
colOut += gWeights[i] * col;
}
return colOut;
}

测试表明,这种双重方法可以将性能提高近一倍,并随着核尺寸的增加而增加。然而,对于非常大的核,算法会受到内存带宽(硬件特定)的限制,收益递减:在Intel GPU上,核尺寸达到并超过127x127(RGBA8)时,效果开始明显,但在独立GPU上可能更高(未测试)。

在离散桌面GPU(Nvidia GTX 650)和带有集成显卡的Bay Trail平板CPU(Atom Z3770)上,测试(7x7、35x35、127x127)核尺寸时,观察到非常相似的性能差异。
FastBlurs示例展示了这种优化的Gaus模糊滤镜实现,并包含GLSL着色器代码生成器(在GaussianBlur.h中)以生成任何自定义核大小。此外,可以通过运行示例,选择所需的核宽度并反复单击“高斯模糊”界面按钮几次来生成GLSL代码。
在较低分辨率下工作
我们已经有了一个很好的高斯模糊实现——但是我们游戏中的“受击”效果需要一个大的模糊核,而且我们的目标硬件是高分辨率移动设备。高斯模糊仍然有点太昂贵了,我们能做得更好吗?
事实证明,牺牲一些质量是很常见的,因为模糊是一个低通滤镜(保留低频信号,衰减高频信号),所以可以将其降采样到较小分辨率的缓冲区,例如1/2 x 1/2,执行模糊效果,然后再升采样回原始帧缓冲区。对于模糊滤镜,这有两个主要好处:
- 对于1/2 x 1/2的中间模糊缓冲区,需要处理的像素数量减少了4倍。
- 相同核大小在较小缓冲区中覆盖2 x 2的更大区域,因此对于相同的最终效果,模糊核在每个维度上应减小1/2。
这两者结合起来,使得使用1/2 x 1/2中间缓冲区时,相似效果的成本降低了8倍,尽管有与之相关的下采样固定成本,以及将结果上采样回主缓冲区的固定成本。因此,这仅对例如7x7及以上(较小的核也不足以隐藏由于下采样和上采样造成的质量损失)的模糊核有意义。

主要的缺点是,对于少量模糊(小模糊核),从低分辨率下采样再上采样造成的“块状”图案变得明显,因此如果效果需要淡入/淡出,尤其是在移动图像中,这可能会成为问题。对于淡入淡出效果,这可以通过在模糊的下采样图像和最终图像之间进行插值来解决,以应对小核值。在其他一些情况下,例如使用模糊滤镜产生泛光效果时,低分辨率中间缓冲区的问题甚至会被运动和泛光功能进一步减弱,因此通常需要反复试验才能找到在质量与性能方面更优化的模糊滤镜分辨率。
为了强调尽可能在较小的(1/2 x 1/2,甚至1/4 x 1/4)中间缓冲区中工作的重要性,我使用了随附的示例来测量在大型桌面AMD R9-290X GPU上模糊2560x1600图像以及在Nexus 7平板电脑上模糊1280x720图像所需的时间。
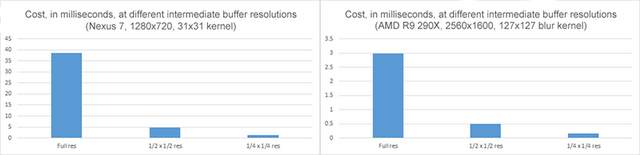
在R9-290X的情况下,全分辨率图像使用127x127的大模糊核,计算时间约为3毫秒。使用1/2 x 1/2的中间缓冲区需要63x63的模糊核,并在0.5毫秒内执行,以1/6的时间产生几乎相同的图像质量;1/4 x 1/4的中间缓冲区仅需要0.17毫秒。Nexus 7 Android平板电脑上的性能差异按比例相似(运行适当的、小得多的工作负载)。
“Kawase模糊”滤镜
我们已经有了一个优化的高斯模糊实现,并且我们正在以1/2 x 1/2的分辨率处理它,用于我们的HDR泛光效果(在一个假设的游戏开发场景中),但它仍然每帧花费我们3毫秒。我们能做得更好吗?将分辨率降到1/4 x 1/4看起来不够好,因为它会导致泛光在运动时闪烁,并且减小核大小无法产生足够的效果。
嗯,一种针对泛光的替代方案是(已经提到的)http://software.intel.com/en-us/articles/compute-shader-hdr-and-bloom(基于“HDR:Bungie之道。微软Gamefest 2006.”)。然而,它需要多个渲染目标,实现和维护起来有点混乱,作为通用模糊算法重用性不强,并且默认情况下固定为一个核大小(使效果依赖于屏幕分辨率,并且艺术家不容易“调整”)。
然而,事实证明,有一种通用模糊算法的性能甚至可以优于我们优化的高斯解决方案——尽管在滤镜质量/正确性方面存在权衡(它提供的分布远非理想,但对于大多数游戏引擎目的来说是可以接受的)——由Masaki Kawase在其GDC2003演讲“DOUBLE-S.T.E.A.L (Wreckless) 中的帧缓冲区后处理效果”中介绍(www.daionet.gr.jp/~masa/archives/GDC2003_DSTEAL.ppt)。最初用于泛光效果,可以将其推广到在外观上与高斯模糊密切匹配。
它是一个多通道滤镜,每个通道使用前一个通道的结果,并应用少量模糊,累积足够的模糊以近似高斯分布。在每个通道中,新的像素值是距离像素中心可变距离的矩形图案中16个样本的平均值。通道数和距中心的采样距离根据预期结果而变化。

这种方法充分利用GPU采样器硬件(http://www.realworldtech.com/ivy-bridge-gpu/6/),通过一次采样调用获取四个像素(每通道4个采样/16个像素值)。实现与特定高斯分布核大小接近等效所需的通道数量,与高斯核大小的增加呈非线性关系。
当前,用于匹配特定高斯滤镜核的通道数和四个采样的核模式是基于经验比较的——在本文的未来更新中将探讨一种更自动的方法。
该示例提供了一个图表显示,用于更精确地“匹配”不同技术以模拟高斯滤镜分布,并确保分布的正确性。
质量

(左:沿x轴的中间横截面;右:俯视图)




性能
尽管在几乎所有测试案例中性能都更好,但Kawase模糊滤镜的主要影响在于较大的核,并且一些硬件从中受益更多(特别是Nexus 7)。此外,“更大”的GPU需要更大的工作纹理才能使差异变得明显。

(由于大核问题,Nexus 7未显示127x127高斯核的数据)

(英特尔第四代超级本GPU到独立GPU)
该示例测量了绘制基本场景(截图和移动三角形)与绘制基本场景加上下采样到工作纹理大小、应用模糊并将结果应用回全分辨率帧缓冲区纹理之间的差异。
结果显示,Kawase模糊在各种硬件、分辨率和核大小上,计算时间似乎比优化的高斯模糊滤镜实现少1.5到3.0倍,尽管它在更大的核和更大的工作纹理尺寸以及低功耗GPU上表现尤为出色。
不幸的是,尽管该示例涵盖了高达127x127的大小,但我还没有(截至目前)一种确定性方法来生成Kawase核以匹配任意大小的高斯滤镜——这是我计划在下一篇文章中介绍的少数几件事之一。
移动平均计算着色器版本
最后,事实证明,通过多次应用“移动平均”盒式滤镜,可以设计出一种简单的、每像素线性时间(O(1)复杂度)的模糊滤镜。然而,由于较高的固定成本,这种方法似乎只在非常大的模糊核尺寸下才开始达到现代GPU上高斯/Kawase滤镜的性能,因此它可能只适用于非常特定的场景。
尽管如此,它仍然是算法工具箱中一个很酷的东西,并且肯定会派上用场。Ryg的优秀文章(http://fgiesen.wordpress.com/2012/07/30/fast-blurs-1/)中详细解释了移动平均盒式滤镜,但这里是简短的总结:
- 盒式滤镜是一种图像滤镜,它将每个像素的值替换为m x n个相邻像素的平均值(所有归一化值都相等的卷积滤镜核)。

3x3盒式滤镜核
- 2D盒式滤镜可以通过进行2次可分离的1D水平/垂直通道来实现,与高斯可分离滤镜的描述方式相同,复杂度为O(n)。然而,除此之外,还可以使用“**移动平均**”来完成每个垂直和水平通道,其复杂度为O(1)。
移动平均基本上对整个列(或行)进行一次遍历,遍历整个长度
- 对于前*核大小*个元素,创建总和并将平均值写入输出。
- 然后,对于每个新元素,从平均值中减去不再被核大小覆盖的元素的值,并加上右侧的值。然后将平均和(除以核大小)写入输出。
这样做的效果是,对于足够大的数组大小,计算时间不会随核大小的增加而增加。

用于水平移动平均盒式滤镜通道的GLSL代码
vec3 colourSum = imageLoad( uTex0, ivec2( 0, y ) ).xyz * float(cKernelHalfDist);
for( int x = 0; x <= cKernelHalfDist; x++ )
colourSum += imageLoad( uTex0, ivec2( x, y ) ).xyz;
for( int x = 0; x < cTexSizeI.z; x++ )
{
imageStore( uTex1, ivec2( x, y ), vec4( colourSum * recKernelSize, 1.0 ) );
// move window to the next
vec3 leftBorder = imageLoad( uTex0, ivec2( max( x-cKernelHalf, 0 ), y ) ).xyz;
vec3 rightBorder = imageLoad( uTex0, ivec2( min( x+ cKernelHalf +1, cTexSizeI.z-1 ), y ) ).xyz;
colourSum -= leftBorder;
colourSum += rightBorder;
}
- 虽然单次盒式滤镜处理对于大多数目的来说无法提供足够好的模糊效果,但多次对同一数据集重复应用盒式滤镜可以近似高斯分布(参见http://en.wikipedia.org/wiki/Central_limit_theorem)。


随附的示例使用两通道版本,因为它在合理的性能下提供了足够好的质量,尽管在某些情况下三通道版本确实提供了明显更好的结果。
性能
下图展示了2通道盒式移动平均(Box Moving Averages)与高斯(Gauss)和Kawase滤镜的性能。正如预期的那样,移动平均滤镜的成本与核大小无关,并且在核大小约为127x127时开始变得更优(尤其是在内存受限的Ultrabook HD4400 GPU上)。

几点说明
- 在所有情况下,Windows OpenGL 和 Android OpenGLES 在 Bay Trail (Atom Z3775) 上的性能几乎相同,因此这些数字涵盖了这两个平台。
- Nexus 7 不支持移动平均滤镜,因为它缺少计算着色器支持。
- 在测试的AMD硬件上,多通道计算着色器存在问题,其中对“
glMemoryBarrier(GL_SHADER_IMAGE_ACCESS_BARRIER_BIT)”的调用似乎无法正常工作,需要改为调用“glFinish()”,这会使性能数据的正确性失效,因此省略了这些数据。 - 在测试的Nvidia硬件上,性能稳定但出乎意料地慢,这表明算法实现可能并非最优(例如,计算着色器组调度大小存在很大的性能差异,我无法为两种不同的Nvidia GPU找到最佳匹配),因此在进一步调查之前省略了这些数据。
这也说明了要达到计算着色器工作负载的“最佳点”以实现最优执行是多么棘手,因为它需要供应商特定(甚至供应商GPU代次特定)的调优。
摘要

我希望这篇文章能为您提供一些有用的信息,关于
- 如何潜在地让您的高斯模糊滤镜运行得更快(以及源代码生成器)。
- 如何编写和使用Kawase滤镜,这是从性能角度看,除了最小核尺寸之外,高斯模糊的一个很好的替代方案。这在从Nexus 7平板电脑到英特尔超级本以及独立GPU的各种硬件上都适用。
- 在支持计算着色器的平台上(Intel的Bay Trail是Android上第一个支持OpenGL ES3.1的平台),两(或更多)通道移动平均盒式滤镜在非常大的核尺寸下表现会更好。然而,计算着色器方法只在特定场景下才有实际意义,并且需要硬件特定的调优。
如果您有任何建议,发现任何错误或有任何其他类型的评论,请在页面底部的评论区留下。
一些额外说明
GPU内存布局和缓存友好性
- 由于纹理缓存的原因,每个像素使用大核可能比使用较小局部核访问的多通道更糟糕(而且大核是浪费且低效的)。
- 由于非线性、平铺的纹理内存寻址(参见http://www.x.org/wiki/Development/Documentation/HowVideoCardsWork/#index1h3),进行水平和垂直计算着色器通道的性能基本相同。这仅适用于访问纹理对象,而不适用于以扫描线方式手动寻址缓冲区,在这种情况下,水平通道中的内存访问将更加缓存友好。在这种情况下,在垂直通道之前和之后进行转置可以产生更好的整体性能。
性能分析说明
所有性能分析(示例中的“运行基准测试”按钮)都是通过将内容绘制到所选场景内容大小(1280x720、1600x900、1920x1080和2560x1600)的离屏缓冲区,并将其显示到1280x720视口来完成的,因此这些数字与设备分辨率无关。
首先,通过绘制离屏内容并将其应用到屏幕(1280x720视口)来测量基线成本。
然后,测量工作负载成本(绘制离屏场景、下采样、应用滤镜、上采样、绘制到屏幕)
基线与工作负载之间的差异显示在屏幕上。
在分析时,此过程循环8次,然后绘制GUI并显示在屏幕上以减少干扰。V-sync被禁用(尽管这似乎在Nvidia最新驱动程序上不起作用,因此必须在图形控制面板中手动禁用)。
我希望在更新中涵盖的内容
- 通用(非整数)核大小支持和效果的淡入/淡出
该示例提供了一个通用高斯核生成器,适用于任何 n*4-1 核大小,但不适用于其间的任何大小。“Kawase模糊”有多种预设,但目前没有一种通用的方法来计算这些预设。移动平均实现与高斯模糊类似。
接下来我想做的是
- 为高斯滤镜添加对任何非整数核大小的支持。
- 为任何给定高斯核创建Kawase通道的数学正确方法,或一个暴力系统来预生成这些预设,并处理非整数核大小。
- 实现移动平均滤镜的非整数支持。
- 可能会实现一个简单的景深/HDR泛光效果,用于测试目的,使用Kawase滤镜。 - 更优化的移动平均计算着色器实现
需要研究更优化的内存访问模式和GPU线程调度 - 更好的高斯滤镜实现?
任何想法——请发送给我(我已收到一个很好的建议,正在研究中)!:)
代码示例
代码示例使用OpenGL for Windows平台和OpenGL ES for Android平台(NDK)构建,演示了高斯、Kawase和移动平均(计算着色器)模糊滤镜,并为各种核大小和屏幕分辨率提供了基准测试支持。
当检测到OpenGL ES 3.1支持时(例如在英特尔Bay Trail Android平板电脑上),将启用移动平均计算着色器路径。

附带源代码和二进制文件的软件包如下所示。
- FastBlurs.zip (12.05 MB) 立即下载