
Filio - 分布式文件管理
分布式文件管理
引言
这是一个分布式(网格)文件搜索、查找重复项、全文索引工具,使用HTTP/TCP连接,通过多线程实现极高速度,自动检测物理硬盘并利用NTFS USN日志加速,并定制化序列化缓存哈希和全文。
更多功能即将推出……这个应用程序是一个严肃的项目,并且正在快速改进,每隔几天就会增加一个主要功能。
当前特性
- 分布式:通过互联网使用HTTP或TCP在不同的计算机上搜索
- 安全访问:内置RBAC
- 快速:多线程并发网格计算
- 高效:压缩哈希,带有本地序列化存储和压缩网络传输的全文索引
- 智能
- 检测不同的物理硬盘(非分区),并自动通过并行计算加速
- 检测NTFS并自动使用USN日志,使文件搜索速度提高10倍
- 可扩展:支持不同的全文索引接口
背景
文件搜索是一个非常古老的话题。看起来我似乎在重新发明轮子,但最终我向你保证我不是。
最初,我只是想找一个应用程序来搜索我的3TB硬盘,以快速找到重复文件。市面上有很多非常好的商业产品,但是,我自言自语,为什么不自己做一个呢,既能提高技能又能做出自己的东西。最后就有了这个严肃的应用程序。
理论
要查找重复文件,你需要确定重复条件,是按文件名、大小、内容等。通常,我们使用MD5来获取文件的哈希值,以确保两个文件完全相同,尽管MD5最近已被证明不安全。但是,你可以选择SHA1进行哈希,这完全取决于你。
获取键(文件名/大小/内容哈希等)后,我们将其放入一个Dictionary中,这样我们就可以轻松地知道哪些是重复文件。
代码历史
我的应用程序已经有6个版本
- 我只是简单地哈希所有文件,它有效,但非常慢,因为它遍历所有磁盘文件内容,想象一个装满文件的3TB硬盘。
- 然后我改为使用文件名/大小/修改日期等来首先获取重复项。如果大小不同,它们就不会相同,对吗?
- 但我仍然不满意它的速度。如今,大多数CPU都有多核,我们应该通过使用多线程来利用多核的强大功能。
- 经过几次测试,多线程适用于文件信息搜索(
Directory.GetFiles),但不适用于文件内容读取(哈希),所以我只在文件信息搜索中使用多线程。 - 但我仍然不满意速度。:)我发现我可以动态识别文件是否位于不同的物理硬盘(不是同一硬盘中的不同分区)中,如果是,我们仍然可以使用多线程来加速。我发现我可以使用快速定制序列化来存储哈希值,并且每次我对文件进行哈希时,我首先查找序列化存储,如果存在匹配项,我直接使用它,而无需进行缓慢的哈希运算。
- 好的,现在速度还不错。但这不太有用,因为你只能在自己的计算机内进行搜索。我想到我可以实现一个分布式文件搜索,使用HTTP/TCP进行通信。最后,我们做到了。:)
Using the Code
使用代码非常简单。
本地搜索完全相同的文件
string duplicateFolder = @"d:\backup";
Dictionary<string, MatchFileItem> result;
BaseWork worker = new WorkV6();
result = worker.Find(new FileURI[]
{ new FileURI(@"c:\download\"), new FileURI(duplicateFolder)}
, new string[] { }, "", SearchTypes.Size | SearchTypes.Name, MatchTypes.ContentSame);
List<string> duplicatedFiles = worker.FindAll(result, duplicateFolder);
分布式搜索包含字符串的文件(全文)
首先,我们需要初始化一些东西
WorkUtils.Initialize(new KeyValuePair<string, string>()
, CompressionMethods.GZip
, null, true, true, 5
, null, null, null);
服务器
BaseManager manager = new WorkV6HTTPManager();
Role role = new Role("user");
role.AddFilePath(@"c:\temp\New Folder");
role.AddUser(new UserAuth("user", "pass"));
role.AddRight(UserRights.Discover);
role.AddRight(UserRights.Search);
role.AddRight(UserRights.Delete);
manager.Roles.AddRole(role);
manager.Progress += new EventHandler<ProgressEventArgs>(OnWorkProgress);
manager.Request += new EventHandler<DataTransferEventArgs>(OnManagerRequest);
manager.Start(8880);
客户端
FileURI remoteFolder = new FileURI(@"202.2.3.4:8880/e:\temp\New Folder",
"user", "pass", 0
, ObjectTypes.RemoteURI);
Dictionary<string, MatchFileItem> result;
result = Worker.Find(new FileURI[] { new FileURI(@"c:\download\"), remoteFolder }
, new string[] { }, "YOUR KEYWORD HERE"
, SearchTypes.Size
, MatchTypes.ContentExtract);
List<string> matchFiles = Worker.FindAll(result, string.Empty);
机制
看起来很简单,是吧?但其底层机制真的很复杂。首先,看看工作流程
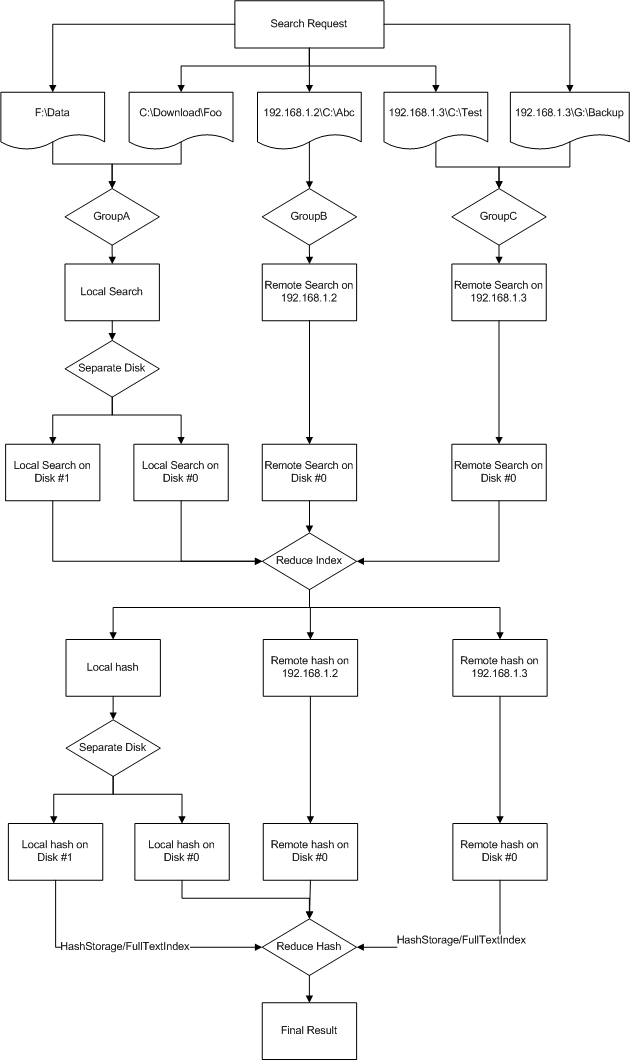
如你所见,整个搜索任务由两大步组成:针对文件名/大小等进行文件信息搜索,之后,我们找到内容相同的文件。
对于分布式搜索,情况更加复杂。第一步是返回来自远程计算机的所有文件信息,因为在合并结果之前你无法判断哪些文件是相同的。
快速
整个应用程序的目标是快速。它使用各种技术来提升性能。
- 哈希:我首先使用文件名/大小来过滤文件,然后我使用这里发现并改进的定制序列化来缓存哈希值。
- 文件信息搜索:实现这里发现的NTFS USN Journal,以极快的速度获取文件名,无需递归遍历文件夹,并自动检测不同的物理硬盘然后使用多线程。
- 压缩:实现全文内容和网络传输的压缩。
- 并行处理:此处可查。
不仅仅是重复文件搜索
它可以搜索重复文件,也可以只搜索文件名,甚至文件内容(包含或全文)。
技术细节
文件搜索
信息搜索
通常,我们使用Directory.GetDirectories()与SearchOption.AllDirectories选项递归获取文件夹内的所有文件,但如果文件夹包含大量文件,例如“Program Files”文件夹,你将需要等待很长时间。我自行进行递归搜索,以便能够控制进程,并添加事件逻辑以减少CPU节流。在每个文件夹中,我根据SearchTypes选项使用文件名、大小、修改日期等进行冲突处理。详情请参阅WorkV6FindFileRunner.FindLocal。
NTFS USN 日志
关于NTFS USN日志,你可以查阅这篇文章:NTFS的主文件表和USN。基本上,NTFS是一个日志文件系统,它跟踪所有文件活动的变化,如添加/删除/修改等。我首先检测用户是否要搜索整个分区,然后识别它是否是NTFS格式,USN日志将生效。它首先使用定制序列化查找本地NTFS存储,如果没有匹配项(第一次),它将直接读取MTF(主文件表),无需递归逐文件夹搜索文件,因此它非常快,快如闪电!下次对于相同的请求,它将读取本地存储,并查找上次快照的更改。详情请参阅LocalNTFSStorage。
哈希
使用 SearchTypes 过滤后,我使用 MD5CryptoServiceProvider 获取哈希值。如果你不信任 MD5,可以选择使用 SHA1CryptoServiceProvider。详情请参阅 WorkUtils.HashMD5File。
哈希值存储在一个自定义序列化文件中。在真正对文件进行哈希处理之前,应用程序会在存储中查找具有相同SearchTypes的文件。如果存在匹配项,则使用存储的值;否则,将计算哈希并将其存储到序列化文件中。详情请参阅LocalHashStorage。
文件比较/匹配
文件比较有四种方法:文件名、内容完全相同、内容包含和内容提取(全文)。
- 文件名:仅根据文件类型选项搜索文件名。
- 内容完全相同:使用哈希搜索完全相同的文件。
- 内容包含:使用关键词搜索包含指定文本的文本文件。
File.ReadAllText(file).IndexOf(keyword, StringComparison.InvariantCultureIgnoreCase)
- 内容提取:它实现了
IFileContentIndex,使用Microsoft内置的IFilter,首先获取文本文件的全文,然后使用string.IndexOf进行匹配。详情请参阅LocalFileContentIndexStorage。
并行处理
目前,我使用C#和.NET 2.0,所以没有.NET 4.0附带的并行处理库,但我使用了此处找到的模拟代码。其机制是使用ThreadPool.QueueUserWorkItem通过ManualResetEvent控制每个任务的状态来运行每个任务,并使用WaitHandle.WaitAll等待每个任务完成。详情请参阅ParallelProcessor.ExecuteParallel。
线程安全
在多线程世界中,这是一个常见问题。在.NET 2.0中,你需要对Dictionary进行锁定。目前,我使用的是此处找到的SynchronizedDictionary。当然,我们仍然可以使用带有HashTable.Synchronized(YourHashTable)的装箱HashTable。如果你正在使用.NET 4.0,可以使用ConcurrentDictionary。
除了字典,你还需要注意所有文件流的锁定。
任务拆分
分布式计算中最重要的是将任务拆分成小块,并让不同的计算机/线程执行每个任务。首先,我们将文件夹拆分成几个任务组,然后根据远程/本地文件夹分离任务。详情请参阅WorkV6FindFileRunner。
所有文件信息搜索任务完成后,它会减少结果并再次拆分任务,根据MatchTypes进行文件比较。对于本地文件夹,它会自动识别文件夹是否位于不同的物理硬盘上,如果是,则使用多线程。详情请参阅WorkV6FindResultRunner。
分布式
这是整个应用程序的核心。其机制是在每台计算机上运行一个侦听器,等待远程命令。
数据传输
它不使用XML作为容器,而是使用定制的二进制缓冲区。为了性能要求,内容经过压缩。
协议
目前,它支持HTTP和TCP。客户端将首先尝试通过HTTP连接,如果失败则回退到TCP。每个请求都通过异步完成,以避免阻塞网络。
- HTTP:每个请求内容都通过
Request.GetRequestStream通过WorkUtils.SendHTTPRequest进行POST和压缩。在服务器端,一个HTTPListener正在等待每个HTTPListenerRequest。对于每个HTTPListenerRequest,它会调用BaseManager中的ProcessRequest来处理Request.InputStream。详情请参阅WorkV6HTTPManager。HTTPListener非常特殊,你应该首先使用HTTPListener.IsSupported,因为它只在winxp sp2+上运行。它基于http.sys构建,原生不支持SSL,但你可以使用可以从MSDN下载的HTTPCfg.exe。 - TCP:客户端使用
AsynchronousClient连接到服务器,服务器使用AsynchronousSocketListener等待每个请求,并在Received事件中处理请求。详情请参阅WorkV6TCPManager。
提供者模式
在 v1.70 版本中,Filio 引入了提供者模式,现在它通过 BaseWorkProvider 支持不同类型的协议。
以前
ip:port /remoteaddress/remotefile
现在
protocol://ip:port/remoteaddress/remotefile
你可以发挥想象力,添加对多种存储的支持,例如
c:\temp\abc.txt
\\lancomputer\temp\abc.txt
http://1.2.3.4:88/foo/abc.txt
tcp://1.2.3.4:55/foo/abc.txt
ftp://1.2.3.4:21/foo/abc.txt
pop3://1.2.3.4:101/foo/abc.txt
skydrive://foo/abc.txt
dropbox://foo/abc.txt
AmazonS3://foo/abc.txt
flicker://foo/abc.jpg
facebook://foo/abc.jpg
关注点
我非常热爱开源和性能,通过开发这个应用程序学到了很多。因为我从开源世界中获得了不少帮助,所以我决定将这个应用程序开源在http://filio.codeplex.com/。
已知问题
IFilter在多线程环境下无法正常工作。- NTFS USN Journal 可能导致
ExcutionEngineException问题,并且你无法继续。
待办事项
- 文件上传、下载和同步
- 通过提供者模式扩展支持Microsoft Azure、Amazon s3等云存储
- 将代码移植到.NET 4.0,利用PPL/Linq等新功能的强大功能
历史
- 2010-8-02: v1
- 2010-8-11: v2: Filio v1.70