
基于边缘的模板匹配
实现基于边缘的模板匹配或模式匹配算法。
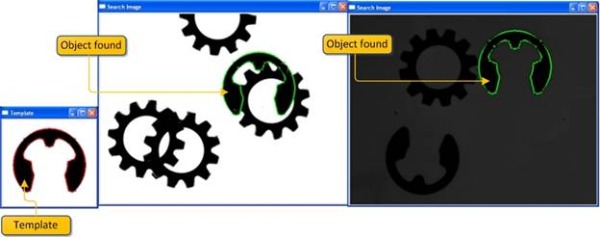
引言
模板匹配是一个图像处理问题,用于在搜索图像中找到目标对象的位置,而其姿态(X, Y, θ)是未知的。在本文中,我们实现了一种使用对象边缘信息来识别搜索图像中对象的算法。
背景
模板匹配由于其速度和可靠性问题,本质上是一个难题。解决方案应能鲁棒地应对亮度变化,即使对象部分可见或与其他对象混合,最重要的是,算法应具有计算效率。解决这个问题主要有两种方法:灰度值匹配(或基于区域的匹配)和基于特征的匹配(非基于区域)。
基于灰度值的方法:在基于灰度值匹配中,归一化互相关(NCC)算法由来已久。这通常是通过在每一步减去均值并除以标准差来完成的。模板 t(x, y) 与子图像 f(x, y) 的互相关是

其中 n 是 t(x, y) 和 f(x, y) 中的像素数量。 [Wiki]
尽管这种方法对线性光照变化具有鲁棒性,但在对象部分可见或与其他对象混合时,算法会失败。此外,由于需要计算模板图像中所有像素与搜索图像之间的相关性,该算法计算成本很高。
基于特征的方法:在图像处理领域,有几种基于特征的模板匹配方法正在使用。例如,基于边缘的对象识别,其中对象的边缘是用于匹配的特征;在广义霍夫变换中,将使用对象的几何特征进行匹配。
在本文中,我们实现了一种使用对象边缘信息来识别搜索图像中对象的算法。此实现使用开源计算机视觉库作为平台。
编译示例代码
我们使用 OpenCV 2.0 和 Visual Studio 2008 来开发此代码。要编译示例代码,我们需要安装 OpenCV。
OpenCV 可以从 这里 免费下载。OpenCV(Open Source Computer Vision)是一个用于实时计算机视觉的编程函数库。下载 OpenCV 并将其安装在您的系统上。安装信息可以从 这里 阅读。
我们需要配置我们的 Visual Studio 环境。此信息可以从 这里 阅读。
算法
在此,我们解释一种基于边缘的模板匹配技术。边缘可以定义为数字图像中图像亮度急剧变化或不连续的点。从技术上讲,它是一个离散微分运算,计算图像强度函数梯度的近似值。
有许多边缘检测方法,但大多数可以分为两类:基于搜索的方法和基于零交叉的方法。基于搜索的方法首先计算边缘强度度量,通常是一阶导数表达式,如梯度幅度,然后使用计算出的边缘局部方向估计(通常是梯度方向)来搜索梯度幅度的局部方向最大值。在这里,我们使用的是 Sobel 称之为 Sobel 算子的实现方法。该算子计算每个点的图像强度梯度,给出从亮到暗的最大可能增加的方向以及该方向的变化率。
我们在匹配中使用 X 方向和 Y 方向的这些梯度或导数。
该算法包含两个步骤。首先,我们需要创建一个模板图像的基于边缘的模型,然后我们使用该模型在搜索图像中进行搜索。
创建基于边缘的模板模型
我们首先从模板图像的边缘创建一个数据集或模板模型,该模型将用于在搜索图像中查找该对象的姿态。
在这里,我们使用了 Canny 边缘检测方法的一个变体来查找边缘。您可以在 这里 阅读更多关于 Canny 边缘检测的内容。对于边缘提取,Canny 使用以下步骤
步骤 1:查找图像的强度梯度
对模板图像使用 Sobel 滤波器,该滤波器返回 X (Gx) 和 Y (Gy) 方向的梯度。从这个梯度,我们将使用以下公式计算边缘幅度和方向
![]()
![]()
我们正在使用一个 OpenCV 函数来查找这些值。
cvSobel( src, gx, 1,0, 3 ); //gradient in X direction
cvSobel( src, gy, 0, 1, 3 ); //gradient in Y direction
for( i = 1; i < Ssize.height-1; i++ )
{
for( j = 1; j < Ssize.width-1; j++ )
{
_sdx = (short*)(gx->data.ptr + gx->step*i);
_sdy = (short*)(gy->data.ptr + gy->step*i);
fdx = _sdx[j]; fdy = _sdy[j];
// read x, y derivatives
//Magnitude = Sqrt(gx^2 +gy^2)
MagG = sqrt((float)(fdx*fdx) + (float)(fdy*fdy));
//Direction = invtan (Gy / Gx)
direction =cvFastArctan((float)fdy,(float)fdx);
magMat[i][j] = MagG;
if(MagG>MaxGradient)
MaxGradient=MagG;
// get maximum gradient value for normalizing.
// get closest angle from 0, 45, 90, 135 set
if ( (direction>0 && direction < 22.5) ||
(direction >157.5 && direction < 202.5) ||
(direction>337.5 && direction<360) )
direction = 0;
else if ( (direction>22.5 && direction < 67.5) ||
(direction >202.5 && direction <247.5) )
direction = 45;
else if ( (direction >67.5 && direction < 112.5)||
(direction>247.5 && direction<292.5) )
direction = 90;
else if ( (direction >112.5 && direction < 157.5)||
(direction>292.5 && direction<337.5) )
direction = 135;
else
direction = 0;
orients[count] = (int)direction;
count++;
}
}
找到边缘方向后,下一步是关联图像中可追溯的边缘方向。有四种可能的方向描述周围像素:0 度、45 度、90 度和 135 度。我们将所有方向分配给其中任何一个角度。
步骤 2:应用非最大值抑制
在找到边缘方向后,我们将执行非最大值抑制算法。非最大值抑制沿着边缘方向追踪左右像素,如果当前像素的幅度小于左右像素的幅度,则抑制当前像素。这将产生一个细致的图像。
for( i = 1; i < Ssize.height-1; i++ )
{
for( j = 1; j < Ssize.width-1; j++ )
{
switch ( orients[count] )
{
case 0:
leftPixel = magMat[i][j-1];
rightPixel = magMat[i][j+1];
break;
case 45:
leftPixel = magMat[i-1][j+1];
rightPixel = magMat[i+1][j-1];
break;
case 90:
leftPixel = magMat[i-1][j];
rightPixel = magMat[i+1][j];
break;
case 135:
leftPixel = magMat[i-1][j-1];
rightPixel = magMat[i+1][j+1];
break;
}
// compare current pixels value with adjacent pixels
if (( magMat[i][j] < leftPixel ) || (magMat[i][j] < rightPixel ) )
(nmsEdges->data.ptr + nmsEdges->step*i)[j]=0;
Else
(nmsEdges->data.ptr + nmsEdges->step*i)[j]=
(uchar)(magMat[i][j]/MaxGradient*255);
count++;
}
}
步骤 3:执行滞后阈值
使用滞后进行阈值处理需要两个阈值:高和低。我们应用高阈值来标记我们相当确定是真的边缘。从这些边缘开始,利用先前导出的方向信息,可以跟踪图像中的其他边缘。在跟踪边缘时,我们应用较低的阈值,允许我们跟踪边缘的微弱部分,只要我们找到一个起点。
_sdx = (short*)(gx->data.ptr + gx->step*i);
_sdy = (short*)(gy->data.ptr + gy->step*i);
fdx = _sdx[j]; fdy = _sdy[j];
MagG = sqrt(fdx*fdx + fdy*fdy); //Magnitude = Sqrt(gx^2 +gy^2)
DirG =cvFastArctan((float)fdy,(float)fdx); //Direction = tan(y/x)
////((uchar*)(imgGDir->imageData + imgGDir->widthStep*i))[j]= MagG;
flag=1;
if(((double)((nmsEdges->data.ptr + nmsEdges->step*i))[j]) < maxContrast)
{
if(((double)((nmsEdges->data.ptr + nmsEdges->step*i))[j])< minContrast)
{
(nmsEdges->data.ptr + nmsEdges->step*i)[j]=0;
flag=0; // remove from edge
////((uchar*)(imgGDir->imageData + imgGDir->widthStep*i))[j]=0;
}
else
{ // if any of 8 neighboring pixel is not greater than max contraxt remove from edge
if( (((double)((nmsEdges->data.ptr + nmsEdges->step*(i-1)))[j-1]) < maxContrast) &&
(((double)((nmsEdges->data.ptr + nmsEdges->step*(i-1)))[j]) < maxContrast) &&
(((double)((nmsEdges->data.ptr + nmsEdges->step*(i-1)))[j+1]) < maxContrast) &&
(((double)((nmsEdges->data.ptr + nmsEdges->step*i))[j-1]) < maxContrast) &&
(((double)((nmsEdges->data.ptr + nmsEdges->step*i))[j+1]) < maxContrast) &&
(((double)((nmsEdges->data.ptr + nmsEdges->step*(i+1)))[j-1]) < maxContrast) &&
(((double)((nmsEdges->data.ptr + nmsEdges->step*(i+1)))[j]) < maxContrast) &&
(((double)((nmsEdges->data.ptr + nmsEdges->step*(i+1)))[j+1]) < maxContrast))
{
(nmsEdges->data.ptr + nmsEdges->step*i)[j]=0;
flag=0;
////((uchar*)(imgGDir->imageData + imgGDir->widthStep*i))[j]=0;
}
}
}
步骤 4:保存数据集
提取边缘后,我们将所选边缘的 X 和 Y 导数以及坐标信息保存为模板模型。这些坐标将被重新排列,以使起点成为质心。
查找基于边缘的模板模型
算法中的下一个任务是使用模板模型在搜索图像中查找对象。我们可以看到我们从模板图像创建的模型,它包含一组点:![]() ,以及它在 X 和 Y 方向的梯度
,以及它在 X 和 Y 方向的梯度 ![]() ,其中 *i = 1…n*,*n* 是模板 (T) 数据集中的元素数量。
,其中 *i = 1…n*,*n* 是模板 (T) 数据集中的元素数量。
我们还可以找到搜索图像 (S) 中的梯度 ![]() ,其中 u = 1...搜索图像的行数,v = 1…搜索图像的列数。
,其中 u = 1...搜索图像的行数,v = 1…搜索图像的列数。
在匹配过程中,模板模型应使用相似性度量与搜索图像在所有位置进行比较。相似性度量的想法是通过模板图像和搜索图像的梯度向量在模型数据集中的所有点上的归一化点积之和。这会在搜索图像中的每个点生成一个分数。这可以表述如下

如果模板模型和搜索图像之间存在完美匹配,此函数将返回分数 1。分数对应于搜索图像中可见的对象部分。如果搜索图像中不存在该对象,则分数为 0。
cvSobel( src, Sdx, 1, 0, 3 ); // find X derivatives
cvSobel( src, Sdy, 0, 1, 3 ); // find Y derivatives
for( i = 0; i < Ssize.height; i++ )
{
for( j = 0; j < Ssize.width; j++ )
{
partialSum = 0; // initilize partialSum measure
for(m=0;m<noOfCordinates;m++)
{
curX = i + cordinates[m].x ; // template X coordinate
curY = j + cordinates[m].y ; // template Y coordinate
iTx = edgeDerivativeX[m]; // template X derivative
iTy = edgeDerivativeY[m]; // template Y derivative
if(curX<0 ||curY<0||curX>Ssize.height-1 ||curY>Ssize.width-1)
continue;
_Sdx = (short*)(Sdx->data.ptr + Sdx->step*(curX));
_Sdy = (short*)(Sdy->data.ptr + Sdy->step*(curX));
iSx=_Sdx[curY]; // get curresponding X derivative from source image
iSy=_Sdy[curY];// get curresponding Y derivative from source image
if((iSx!=0 || iSy!=0) && (iTx!=0 || iTy!=0))
{
//partial Sum = Sum of(((Source X derivative* Template X drivative)
//+ Source Y derivative * Template Y derivative)) / Edge
//magnitude of(Template)* edge magnitude of(Source))
partialSum = partialSum + ((iSx*iTx)+(iSy*iTy))*
(edgeMagnitude[m] * matGradMag[curX][curY]);
}
在实际情况下,我们需要加快搜索过程。这可以通过各种方法来实现。第一种方法是利用平均法的性质。在计算相似性度量时,如果我们能设置一个最小分数(Smin)来衡量相似性,我们就不必为模板模型中的所有点进行评估。为了在某个特定点 J 检查部分分数 Su,v,我们必须找到部分和 Sm。点 m 处的 Sm 可以定义如下

很明显,求和的剩余项小于或等于 1。所以,如果我们有 ![]() ,我们可以停止评估。
,我们可以停止评估。
另一个标准是,任何点的部分分数都应大于最小分数。即 ![]() 。使用此条件时,匹配速度会非常快。但问题是,如果先检查对象的缺失部分,部分和就会很低。在这种情况下,该对象实例将不会被视为匹配。我们可以通过另一种标准来修改此方法,在该标准中,我们使用安全的停止标准检查模板模型的第一个部分,其余部分则使用严格的标准,
。使用此条件时,匹配速度会非常快。但问题是,如果先检查对象的缺失部分,部分和就会很低。在这种情况下,该对象实例将不会被视为匹配。我们可以通过另一种标准来修改此方法,在该标准中,我们使用安全的停止标准检查模板模型的第一个部分,其余部分则使用严格的标准,![]() 。用户可以指定一个贪婪参数 (g),其中一部分模板模型以严格的标准进行检查。因此,如果 g=1,则所有模板模型中的点都以严格的标准进行检查,如果 g=0,则所有点都仅以安全的标准进行检查。我们可以按如下方式表述此过程。
。用户可以指定一个贪婪参数 (g),其中一部分模板模型以严格的标准进行检查。因此,如果 g=1,则所有模板模型中的点都以严格的标准进行检查,如果 g=0,则所有点都仅以安全的标准进行检查。我们可以按如下方式表述此过程。
部分分数的评估可以在以下时间停止

// stoping criterias to search for model
double normMinScore = minScore /noOfCordinates; // precompute minumum score
double normGreediness = ((1- greediness * minScore)/(1-greediness)) /noOfCordinates;
// precompute greedniness
sumOfCoords = m + 1;
partialScore = partialSum /sumOfCoords ;
// check termination criteria
// if partial score score is less than the score than
// needed to make the required score at that position
// break serching at that coordinate.
if( partialScore < (MIN((minScore -1) +
normGreediness*sumOfCoords,normMinScore* sumOfCoords)))
break;
这种相似性度量具有几个优点:相似性度量对非线性光照变化不变,因为所有梯度向量都已归一化。由于边缘滤波没有分段,它将显示出对任意光照变化真正的不变性。更重要的是,当对象部分可见或与其他对象混合时,这种相似性度量是鲁棒的。
增强功能
此算法有各种可能的增强。为了进一步加快搜索过程,可以使用金字塔方法。在这种情况下,搜索从低分辨率和较小的图像尺寸开始。这对应于金字塔的顶部。如果在此阶段搜索成功,则搜索将在金字塔的下一级别继续,该级别代表更高分辨率的图像。以这种方式,搜索继续进行,并因此,结果被细化,直到达到原始图像大小,即金字塔的底部。
可以通过扩展该算法以进行旋转和缩放来实现进一步的增强。这可以通过创建用于旋转和缩放的模板模型并使用所有这些模板模型进行搜索来完成。
参考文献
- 机器视觉算法与应用 [Carsten Steger, Markus Ulrich, Christian Wiedemann]
- 数字图像处理 [Rafael C. Gonzalez, Richard Eugene Woods]
- http://dasl.mem.drexel.edu/alumni/bGreen/www.pages.drexel.edu/_weg22/can_tut.html