
使用 Intel® System Studio 调优自动驾驶
Intel® GO™ SDK 为汽车解决方案开发人员提供集成解决方案环境
Lavanya Chockalingam,Intel 公司软件技术咨询工程师
物联网是连接到云的智能设备的集合。“事物”可以小巧简单,如联网手表或智能手机,也可以庞大复杂,如汽车。事实上,汽车正迅速成为世界上最智能的联网设备之一,利用传感器技术和强大的处理器来感知并持续响应周围环境。为这些汽车提供动力需要一套复杂的技术
- 传感器,捕捉激光雷达、声纳、雷达和光学信号
- 传感器融合中心,收集数百万个数据点
- 微处理器,处理数据
- 机器学习算法,需要巨大的计算能力才能使数据智能且有用
成功实现这些汽车创新的巨大机遇,不仅有可能改变驾驶方式,而且有可能改变社会。
Intel® GO™ 汽车软件开发工具包 (SDK)
从汽车到云——以及介于两者之间的连接——都需要自动驾驶解决方案,这些解决方案包括高性能平台、软件开发工具以及数据中心的强大技术。凭借 Intel GO 汽车驾驶解决方案,Intel 将其在计算、连接和云方面的深厚专业知识带入汽车行业。
全球范围内的自动驾驶不仅仅需要汽车内的高性能传感和计算。它需要广泛的数据服务和连接基础设施。这些数据将与所有自动驾驶汽车共享,以持续提高它们准确感知和安全响应周围环境的能力。为了与数据中心、道路基础设施和其他汽车通信,自动驾驶汽车将需要高带宽、可靠的双向通信以及强大的数据中心服务,以便每秒接收、标记、处理、存储和传输海量数据。自动驾驶系统内的软件堆栈必须能够高效地处理苛刻的实时处理需求,同时最大限度地减少功耗。
Intel GO 汽车 SDK 帮助开发人员和系统设计人员通过各种工具最大限度地发挥硬件能力
- 计算机视觉、深度学习和 OpenCL™ 工具包,用于快速开发感知、融合和决策所需的中间件和算法
- 传感器数据标记工具,用于创建深度学习训练和环境建模的“地面真实”数据
- 针对自动驾驶的性能库、领先的编译器、性能和功耗分析器以及调试器,可在功能安全合规的工作流程中实现全栈优化和快速开发
- 示例参考应用程序,例如变道检测和物体规避,以缩短开发人员的学习曲线
Intel® System Studio
Intel 还提供软件开发工具,帮助加速自动驾驶解决方案的上市时间。 Intel System Studio 为开发人员提供各种工具,包括编译器、性能库、功耗和性能分析器以及调试器,这些工具可以最大限度地发挥硬件能力,同时加速开发速度。它是一个全面且集成的工具套件,为开发人员提供先进的系统工具和技术,以帮助加速下一代、功耗高效、高性能和可靠的嵌入式和移动设备的交付。这包括用于
- 构建和优化您的代码
- 调试和跟踪您的代码以隔离和解决缺陷
- 分析您的代码的功耗、性能和正确性
构建和优化您的代码
- Intel® C++ 编译器 :一个高性能、优化的 C 和 C++ 交叉编译器,可以将计算密集型代码卸载到 Intel® HD Graphics。
- Intel® 数学核心库 (Intel® MKL):一套高度优化的线性代数、快速傅立叶变换 (FFT)、向量数学和统计函数。
- Intel® 线程构建块 (Intel® TBB) :C++ 并行计算模板,可提高嵌入式系统性能。
- Intel® 集成性能原语 (Intel® IPP) :一个软件库,提供广泛的高度优化的功能,包括通用信号和图像处理、计算机视觉、数据压缩、加密和字符串操作。
调试和跟踪您的代码以隔离和解决缺陷
- Intel® 系统调试器 :包括一个系统调试功能,提供 OS 内核软件、驱动程序和固件的源代码级调试,以及一个系统跟踪功能,该功能提供了一个 Eclipse* 插件,通过其跟踪查看器增加了访问 Intel® Trace Hub 的能力,提供先进的 SoC 级指令和数据事件跟踪。
- GNU* 项目调试器 (GDB) :这个 Intel 增强版 GDB 用于在基于 Intel® 体系结构的系统上本地和远程调试应用程序。
分析您的代码的功耗、性能和正确性
- Intel® VTune™ Amplifier :这个软件性能分析工具适用于开发串行和多线程应用程序的用户。
- Intel® Energy Profiler :使用 SoC Watch 工具在目标平台上收集的与功耗相关数据的平台级功耗分析器。
- Intel® Performance Snapshot :提供对性能优化机会的快速、简便的视图。
- Intel® Inspector :一个动态内存和线程错误检查工具,适用于在嵌入式平台上开发串行和多线程应用程序的用户。
- Intel® Graphics Performance Analyzers :实时、系统级的性能分析器,用于优化 CPU/GPU 工作负载。
优化性能
高级热点分析
矩阵乘法是自动驾驶中常用的操作。Intel System Studio 工具,主要是性能分析器和库,可以帮助最大限度地提高性能。考虑一个使用两个嵌套 for 循环的非常简单的矩阵乘法实现示例
void multiply0(int msize, int tidx, int numt, TYPE a[][NUM], TYPE b[][NUM], TYPE c[][NUM], TYPE t[][NUM])
{
int i,j,k;
// Basic serial implementation
for(i=0; i<msize; i++) {
for(j=0; j<msize; j++) {
for(k=0; k<msize; k++) {
c[i][j] = c[i][j] + a[i][k] * b[k][j];
}
}
}
}
高级热点分析是一种快速简便的方法,可以识别性能关键代码段(热点)。Intel VTune Amplifier 执行的周期性指令指针采样可以识别应用程序花费时间最多的代码位置。一个函数可能消耗大量时间,原因要么是其代码执行速度慢,要么是该函数被频繁调用。但任何对这类函数速度的改进都应对整体应用程序性能产生重大影响。
使用 Intel VTune Amplifier 对上述矩阵乘法代码运行高级热点分析,显示总经过时间为 22.9 秒(图 1)。其中,CPU 积极执行了 22.6 秒。CPI 率(即每条指令的周期数)为 1.142,被标记为问题。现代超标量处理器每个周期可以发出四条指令,表明理想的 CPI 为 0.25,但管道中的各种效应——例如长延迟内存指令、分支预测错误或前端的指令饥饿——会增加观察到的 CPI。CPI 为一或更低被认为是好的,但不同的应用程序域将有不同的预期值。在我们的例子中,我们可以进一步分析应用程序,看看 CPI 是否可以降低。Intel VTune Amplifier 的高级热点分析还指出了需要优化的前五个热点函数。

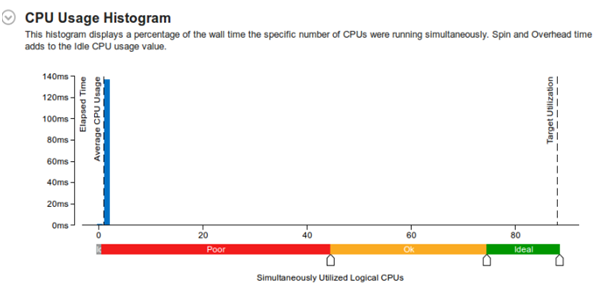
CPU 利用率
如图 2 所示,对原始代码的分析表明,88 个逻辑 CPU 中只有一个被使用。这意味着如果我们能并行化这个示例代码,那么性能提升的空间将非常大。

如下所示的并行化示例代码可带来即时的 12 倍加速(图 3)。此外,CPI 已降至 1 以下,这也是一项显著的改进。
void multiply1(int msize, int tidx, int numt, TYPE a[][NUM], TYPE b[][NUM], TYPE c[][NUM], TYPE t[][NUM])
{
int i,j,k;
// Basic parallel implementation
#pragma omp parallel for
for(i=0; i<msize; i++) {
for(j=0; j<msize; j++) {
for(k=0; k<msize; k++) {
c[i][j] = c[i][j] + a[i][k] * b[k][j];
}
}
}
}


通用探索分析
一旦您使用了基本热点或高级热点分析来确定代码中的热点,您就可以进行通用探索分析,以了解代码在核心管道中的传递效率。在通用探索分析期间,Intel VTune Amplifier 会收集完整的事件列表,用于分析典型的客户端应用程序。它会计算一组预定义的比率用于度量,并有助于识别硬件级性能问题。超标量处理器可以概念性地划分为前端(指令被获取并解码成组成它们的运算)和后端(执行所需计算)两部分。通用探索分析执行此估算,并将所有管道槽位划分为四类
- 包含已发出并退休的有用工作的管道槽位(已退休)
- 包含已发出但被取消的有用工作的管道槽位(错误推测)
- 由于前端问题而无法填充有用工作的管道槽位(受前端限制)
- 由于后端阻塞而无法填充有用工作的管道槽位(受后端限制)
图 4 显示了使用 Intel VTune Amplifier 对并行化示例代码运行通用探索分析的结果。请注意,77.2% 的管道槽位因后端问题而被阻塞。深入到源代码中可以看到这些后端问题发生的位置(图 5,49.4 + 27.8 = 77.2% 受后端限制)。内存问题和 L3 延迟非常高。内存限制指标显示了内存子系统问题如何影响性能。L3 限制指标显示 CPU 有多频繁地因 L3 缓存而停滞。避免缓存未命中(L2 未命中/L3 命中)可以提高延迟并提高性能。


内存访问分析
Intel VTune Amplifier 的内存访问分析识别内存相关问题,如 NUMA(非统一内存访问)问题和带宽限制的访问,并将性能事件归因于内存对象(数据结构)。此信息来自对内存分配/取消分配的检测,以及从符号信息中获取静态/全局变量。
通过选择函数/内存对象/分配堆栈的分组选项(图 6),您可以识别影响性能的内存对象。在 multiply1 函数列出的三个对象中,一个对象的延迟非常高,为 82 个周期。双击该对象会带您到源代码,这表明数组“b”的延迟最高。这是因为数组“b”使用了列主序。交换嵌套循环会将访问更改为行主序并降低延迟,从而获得更好的性能(图 7)。


我们可以看到,尽管示例仍然受后端限制,但它不再受内存限制。它只受核心限制。硬件计算资源短缺或对软件指令的依赖都属于核心限制。因此,我们可以看出机器可能耗尽了乱序执行资源。某些执行单元过载,或者程序的数据或指令流中可能存在限制性能的依赖项。在这种情况下,向量容量使用率较低,这表明浮点标量或向量指令仅使用了部分向量容量。这可以通过向量化代码来解决。
另一个优化选项是使用 Intel Math Kernel Library,它提供了许多数学运算(包括矩阵乘法)的高度优化和多线程实现。dgemm 例程用于乘以两个双精度矩阵
void multiply5(int msize, int tidx, int numt, TYPE a[][NUM], TYPE b[][NUM], TYPE c[][NUM], TYPE t[][NUM])
{
double alpha = 1.0, beta = 0.0;
cblas_dgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
NUM, NUM, NUM,
alpha, (const double *)b,
NUM, (const double *)a,
NUM, beta, (double *)c, NUM);
}
图像调整的性能分析和调优
图像调整在自动驾驶领域的应用中很常见。例如,我们对一个开源 OpenCV* 版本的图像调整运行了 Intel VTune Amplifier 的高级热点分析(图 8)。我们可以看到经过时间为 0.33 秒,并且最主要的热点是 cv:HResizeLinear 函数,该函数消耗了总 CPU 时间的 0.19 秒。

Intel IPP 为开发人员提供了高度优化的、生产就绪的图像处理、信号处理和数据处理(数据压缩/解压缩和加密)应用程序的构建块。这些构建块使用 Intel® Streaming SIMD Extensions(Intel® SSE)和 Intel® Advanced Vector Extensions(Intel® AVX, Intel® AVX2)指令集进行了优化。 图 9 显示了利用 Intel IPP 进行图像调整的分析结果。我们可以看到经过时间减少了一半,并且由于目前只有一个核心被使用,通过 Intel Threading Building Blocks 利用并行性还有进一步提高性能的机会。

结论
Intel GO SDK 中的 Intel System Studio 工具为汽车解决方案开发人员提供了一个集成开发环境,能够构建、调试和跟踪代码,并调优其性能和功耗。这有助于系统和嵌入式开发人员应对他们面临的一些最严峻的挑战
- 加速软件开发,更快地将有竞争力的自动驾驶汽车推向市场
- 快速定位并帮助解决复杂自动驾驶 (AD)、高级驾驶辅助系统 (ADAS) 或软件定义座舱 (SDC) 系统中的缺陷
- 帮助提高性能并降低功耗
所有这些都包含在一个易于使用的软件包中。
了解更多