
面向关系编程 - IDE及敏捷项目管理
4.98/5 (25投票s)
面向关系编程工具的集成开发环境 (IDE)。

目录
- 引言
- ROP 概念和术语回顾
- 为什么,为什么,为什么?
- 敏捷项目管理正规化
- 面向关系编程实践
- 关系
- 关系类型和实例属性
- 实现
- 支持关系创建日期和创建者
- 公开关系类型描述符
- 公开关系事件描述符
- 公开“开始日期”和“结束日期”属性
- 选择列表摘要
- 自动创建“与所有其他实体”关系
- 1:1 关系
- 其他特性
- 只是为了好玩
- 结论
引言
以前的文章
这些文章将引导您了解本系列迄今为止的内容
新功能
欢迎使用面向关系编程 IDE (ROP IDE),如上图所示。这借鉴了之前的工作(如果您是第一次阅读本文,我建议您至少阅读一下之前的文章),它是一个松散的屏幕集合,并将它们组合成一个更具凝聚力的开发和部署框架。它具有以下几个特点
- 可停靠窗口(由 DockPanel Suite 提供)
- 用于创建元模型的元模型树和属性窗口
- 超级用户元模型实例编辑器(如前所述)
- 一个新的用户实体实例编辑器,支持 DevExpress 和 .NET 组件(虽然 DevExpress 版本看起来更好看,但它有自己的一系列问题,尤其是在可折叠面板方面)
目前缺少的是我之前描述的离散控件生成——我主要专注于在 GAPMA 应用程序本身中提高 ROP 的可用性。当然,还有很多其他功能缺失,希望其中大部分,我能想到的,都已在 ROP IDE 本身中记录为用户故事或任务。
要求
对于本文(有关 .NET 和 DevExpress 基于 UI 的内容,请参阅下文),您需要安装
- DockPanel Suite
- GraphViz
- DevExpress 版本 10.2.6(我不应该链接到)
正如我在下面提到的,下一篇文章也将支持 System.Windows.Forms 控件。
如果您由于缺少组件而无法运行 IDE,请直接与我联系。
我们将在本文中完成什么?
除了引入实际的 IDE 之外,本文还将涵盖以下内容
- ROP 的回顾和形式化
- 敏捷术语的正式定义
- 关系实体的正式描述
- 用于选择用户名的 UI 支持
- 在数据集中定义的特定于应用程序的菜单
- 特定于应用程序的变量
- 创建新行时的默认值
- 1:1 关联的自动连接
三个方面,一个应用程序
本系列文章实际上涉及三个方面
- ROP IDE 作为设计工具和应用程序数据编辑器
- 元建模(其中敏捷程序管理应用程序是测试用例)
- 面向关系编程作为与前两个方面一起探索的概念
支持 .NET 和 DevExpress 的 UI
我转向 DevExpress 控件的主要原因(尽管有很多可用的选项,但这是我很久以前就付费购买的)是因为我希望在演示方面能够做一些事情,而这些事情在 .NET 框架自带的控件套件中无法实现。特别是,我希望能够控制 UI 的不同部分,以便我可以隐藏某些部分,从而最大化其他部分可用的空间。例如,将上面的屏幕截图与这个屏幕截图进行比较,后者利用了 DockPanel Suite 和 DevExpress 提供的可折叠 LayoutControlItem 对象

作为 GAPMA 的用户,我发现能够控制界面以专注于手头的任务至关重要,无论是直接数据输入、深入关联还是创建新关联。同样,当我实现离散控件功能(将位于“记录”组中)时,用户将能够轻松地在网格、离散控件或两者中查看数据之间切换。
在 .NET 中,DevExpress 提供的主要 UI 问题功能(可折叠面板)已通过使用自制的、可扩展的面板和分组框进行了镜像,适用于那些不想使用 DevExpress 的人。
重要提示:此功能将在下一篇文章中完全实现。在撰写本文花了一个月时间后,此时完成 System.Windows.Forms 控件支持有点太多了。整个架构已就位,我只需要编写调整大小的面板并使用此处的可折叠分组框,我正在等待作者编写水平折叠功能。
声明式 UI
当我在休息室提出关于使用商业第三方套件的问题时,答案褒贬不一——有些人认为可以,另一些则不然。因此,我决定同时支持 DevExpress 和 .NET 控件。这样做相对容易(每个框架中网格控件的细微差别导致所有控件中最复杂的部分),并且为其中一个或另一个配置应用程序非常简单。因为 UI 是从 XML 生成的,所以我有两个单独的文件夹路径,选择其中一个将实例化所需框架中的控件
protected static string UI = "dotnet\\";
或
protected static string UI = "devexpress\\";
在 XML 中,所需的子类控件库通过以下方式指定
xmlns:ui="UI.DotNet, UI.DotNet"
或
xmlns:ui="UI.DX, UI.DX"
我最初计划对两个框架使用完全相同的 XML,但在我选择不抽象的面板细微差别中存在层次结构问题,因此目前,每个 UI 都有两个单独的 XML 文件。
ROP 概念和术语回顾
如果您是第一次遇到本文,那么现在是回顾 ROP 概念的好时机。
术语
我在处理三个概念时会感到困惑
- ROP 架构本身
- 应用程序的架构
- 应用程序的实体实例
到目前为止,我大部分时间都在写这篇文章,现在才对这三个关键概念有所了解。所以,这里是这三个术语的定义,它们在思考 ROP 时很有用。这是一幅令人困惑的图画,代表了这三个概念

架构
在 ROP 的上下文中,我想专门使用此术语来表示用于定义用于构建应用程序“模型”的“类型”(实体和属性)的架构。我可能还没有成功。架构在“架构”树控件中编辑。
模型
“模型”定义了“应用程序架构”。这些是架构“类型”的“实例”。由于架构(如上定义)是适用于任何类型应用程序的通用架构,因此我们将“应用程序的类型”定义为架构中的“实例”。明白了吗?模型在“超级用户”菜单中编辑。
应用程序
“应用程序”是一个编辑器,在其中创建、编辑模型类型“实例”,并将其与其他应用程序实体实例关联。应用程序在“用户”菜单中编辑。我应该将该菜单项重命名为“应用程序”,但最初的概念是“超级用户”将编辑“模型”,而“用户”将编辑“应用程序”。希望这有道理。
架构编辑器
ROP IDE 提供了一个简单的架构编辑器。架构编辑器为 5 个概念提供了容器
- 属性(字段)
- 实体(表)
- 关系(实体之间的外键“粘合剂”)
- 列表 - “名称”项的集合
- 对 - “名称-名称”项的集合
前三者——属性、实体和关系——是描述在物理表中实现的架构的方式。尽管架构是 XML 序列化的,但当创建 DataSet 时,实体、属性和关系都作为物理表实现。从这个角度来看,您可以使用 ROP 架构编辑器来处理典型的数据库实现,尽管数据库中的许多功能,例如多个主键、多字段外键、字段上的属性(如可空)都缺失了(有意为之)。
ROP 和应用程序架构
ROP 架构(在文件 rop.model 中)是 ROP IDE 用于构建应用程序架构的特定架构。在上一篇文章和本文中,我使用了一个专门设计用于实现 Gloiroksy 敏捷项目管理应用程序 (GAPMA) 的架构。它以 XML 定义,并物理实例化(至少目前是)为一个包含 DataTable 对象和关系的 DataSet。定义是 XML,并持久化到以“.model”结尾的文件中。物理实例化作为序列化的 DataSet 持久化到以“.dataset”结尾的文件中。使用 ROP IDE,您可以单独加载模型和数据集,或同时加载,并且可以单独保存模型和数据集,或同时保存。
ROP 模型
ROP 模型是一个元架构。它是一个可以定义“虚拟”应用程序架构的架构,因此,与 ROP 架构关联的“数据”本身就是一个架构。您可以在这里看到区别

在左侧的树视图中,我们有“实例”集合——在 DataSet 中,这些是 ROP 架构中定义的“类型”的具体实现,因此得名“实例”。然而,ROP 架构定义了本身用于描述应用程序架构的类型,其实体显示在 GAPMA 应用程序右侧的网格中。另一种可视化方式是

模型(应用程序架构) - 超级用户编辑器
应用程序架构由用于特定应用程序(在本例中为 GAPMA)的所有实体、它们的类型及其关系组成。应用程序架构在“超级用户”模型编辑器中进行操作。这包括,类似于架构编辑器树,定义实体、属性和实体之间关系的能力。
但是,与存在主键和外键字段的 ROP 架构不同,您不必为应用程序实体定义这些属性——主键在内部管理,外键关联并非硬编码,而是将允许的关系定义为 ROP 架构的 RelationshipType 实体中的记录。因此,例如,在 ROP 架构中,EntityTypeAttributes 实体,它定义了实体所具有的属性

具有以下字段
- ID:主键
- EntityTypeID:实体类型的外键
- AttributeTypeID:属性类型的外键
- Ordinality:属性定义的顺序
将其与任务的应用程序架构进行对比

它只定义了两个属性:“名称”和“简短描述”。
ROP 关系
在 ROP 架构的“关系”部分,我们描述了参与的表、它们的基数,以及表字段子项与表的物理模型之间关系的外键(主键是隐含的)。例如

上面描述了 EntityInstance 和 EntityType 实体(或者如果您愿意,表,因为这些成为具体的 Table 对象)之间的关系。
应用程序关系
在应用程序架构中,使用 RelationshipType ROP 架构表在“任意两个实体之间”建立关系

这定义了“应用程序实体”之间允许的关系类型。
在内部,当两个实体“实例”关联时,会在 RelationshipInstance 表中(可在 ROP 模型编辑器中的 RelationshipInstance 实体中查看)创建一条记录,将两个“应用程序”实体实例的主键(内部实现)关联起来。RelationshipInstance 表实现了一个复合关联表。
应用程序 - 用户数据编辑器
就像我们为物理模型有一个“超级用户”模型编辑器一样,我们需要为应用程序架构有一个“用户”数据编辑器。在这里,我们可以利用“虚拟”表、它们的列和支持的离散控件的自动生成。我们还可以提供 UI 元素,允许用户导航实体实例之间的关联,由于 UI“知道”模型,因此可以针对所有关联进行通用操作。应用程序实体的典型基于网格的视图如下所示

这是从定义应用程序实体(在本例中为 Project 实体)的属性动态生成的。
为什么,为什么,为什么?
一些答案
为什么是元建模?
元建模提供了一种无需触及数据库架构或编写特定于应用程序的代码即可定义实体、属性及其关系的方法。它还解决了我经常遇到的一个问题,即关系“字段”不足以描述用户所需的实体之间的关系类型,这基本上强制要求使用关联表。在丰富数据集领域,例如执法,尤其如此。
为什么是元模型关系?
在经典的实现中,如果您在两个实体之间创建新的关联,您现在必须返回并修改这些实体的 UI,添加功能以允许用户导航这些关联。使用 ROP IDE,用户会看到所有当前的关联,他/她可以导航到这些关联,以及所有允许的关联类型,他/她可以创建关联。它将权力还给了用户,而不是强迫用户在应用程序实现时的限制内工作。正如我们所有人可能都经历过的那样,应用程序会像二手车一样慢慢过时。
为什么使用复合关联表?
在典型的实现中,上面所示的“用户故事”实体可以具体定义为

请注意,此表有 5 个外键字段。问题如下:
- 我们是否需要其他关联,要求我们更新数据库模型?
- 编写一个查询来询问“此用户故事在哪里被引用了?”有多容易?
- 在上述情况下,用户故事只能与每种类型的一个外键实体相关联。如果您想将用户故事放入多个组中,或者用户故事的任务分散在多个冲刺中,从而用户故事可以与多个冲刺相关联怎么办?
- 如果我们没有预先定义所有关联,并且随着应用程序的开发发现了新的关联怎么办?
- 关于关联本身有用信息怎么办,例如谁创建了它,何时创建,它的生命周期?
上面的第 3 和第 5 项可以通过一个关联表来解决,例如(为了简洁起见,我删除了其他外键)

但这里我们又遇到了另一个问题:对于每个多对多关联,我们都需要一个单独的关联表。在我看来,这相当荒谬,只有(可能)出于性能原因才会这样做。反之,如果我们有一个复合关联表(CAT),我们可以在任意两个实体之间创建关联。在此过程中,我们失去了外键约束的好处,并且出现了性能问题。我相信这两个问题都可以通过以下方式很好地解决:1)不依赖数据库执行级联更新/删除,2)对 CAT 进行适当的索引。
尽管如此,关联表中隐含的关系会丢失一些信息,我稍后将详细描述——但我们希望保留以下问题的答案
- 关系类型是否始终存在,即使由于知识缺失关系本身可能不存在?
- 关系是否有时存在,取决于用户希望如何创建关联?
- 关系是否描述了一个静态关联,除非错误创建,否则永不改变?
- 关系是否描述了一个动态关联,可能只存在于特定的时间段内?
这些都是应该在头等关系公民中明确捕获的重要信息。
为什么是元模型实体和属性?
我在大型数据库中经常遇到的问题之一是未文档化的实体和字段。在上面的架构图中,有“ID”、“名称”、“描述”等属性。我更喜欢对实体和属性采用更正式的方法,其中实体、其属性和它们的关系都可以被文档化。如果文档可以从架构自动生成,那么您就拥有了一个强大的工具。谁真正使用数据库中内置的文档功能?
我们是在查询数据还是关系?
使用 ROP,关系“是”数据。这就是关系成为一流公民的原因。在传统的数据库架构中,关系是外键,它“不是”数据,除非在关联表中表示,而大多数情况下我们不这样做,因为外键建立了一对多关联,这对于大多数关联来说已经足够了。因此,我们失去了关系中的“数据”方面。
训练自己思考查询数据与查询关系之间的区别是一项有用的练习。显然,我们所做的大部分工作都需要使用关系来获取数据——我在这里试图说明的是将关系与数据区分开来,并确定关系的存在本身是否具有价值。
查询数据
这看起来像“这个人的名字是什么?”或者“这些任务的状态是什么?”这里的突出点是,一个人正在获取存储在实体(表)的属性(字段)中的信息。
查询关系
这看起来像这样:“与这个用户故事相关联的所有内容是什么?”或者“这个规范是否有任何相关文档?”或者“我们有没有用于此任务的工具?”这里,突出点不是获取存储在属性中的信息,而是确定某个事物相对于其他事物的存在。这在挖掘大量数据时变得非常重要。例如,在医学图书馆中,我们可能想知道所有疾病中,特定症状可能是哪种疾病的指标。
敏捷项目管理正规化
这有点像上一篇文章对敏捷的复述,但我认为在这里将概念形式化非常值得,这样我们就可以在未来使用一个术语词典,并更简洁地定义敏捷开发真正包含什么,这似乎在敏捷社区中有所欠缺。概念之间的关系是基础性的,由于本系列是关于面向关系编程的,因此强调关系而不是离散术语是有意义的。请注意,关系不是必需的——这些是您可以动态创建的关系,而不是被迫接受它们。
为了形式化的目的,章节标题分为独立的实体,子章节描述了目前已编程到 GAMPA 元模型中的子实体到父实体的关系。当我们查看关系时,显而易见的一件事是,关系中涉及的实体的含义可能会根据关系上下文而变化。例如,与用户故事关联的任务与与缺陷关联的任务具有不同的含义。而含义是信息,可能是 有用的信息,所以我们希望将其作为 ROP 的有用属性牢记在心。
您会注意到,这里有很多您在经典软件开发中会遇到的实体,而敏捷方法论却忽略了它们。我相信对敏捷的批评之一是这些缺失实体造成的,我认为这些实体在成功的项目开发中至关重要,尤其是在大规模开发中。但是,敏捷方法的优势在于,并非所有事情都必须提前定义——我们可以边走边摸索细节,这更准确地反映了现实生活中的努力。
几件事
- 我在这里创建的实体和关系是我发现有用的概念。您可以根据自己的需求添加自己的实体、关系和属性;
- 子章节描述了我在元模型中定义的实体-父关系;
- 每个实体的图表显示了该实体基于关系的完整定义的所有父子关系;
- 如后面再次提到的,所有实体类型都与 Note 和 Document 类型具有自动关系。
我们开始吧!
项目

项目实体是敏捷模型中所有其他实体(涉及应用程序的规范、开发、测试和发布)的容器。根据您的需要,您可能拥有额外的更高级别实体,例如部门(公司中不同部门将有不同的项目在开发中)和公司(如果您是咨询机构,您可能正在为不同的公司处理几个不同的项目)。这些只是更高级别实体的两个例子。
用户故事

用户故事是对应用程序应如何工作、数据如何移动、数据如何报告等方面的描述性叙述。这些可以从高层次的叙述到(例如)工作流、用户交互、UI 要求、规则等的详细描述。
关联
| 用户故事 - 项目 | 用户故事与项目相关联。 |
| 用户故事 - 用户故事 | 用户故事可以是递归的,提供进一步的细化。 |
| 用户故事 - 迭代 | 用户故事通常属于一个迭代。有关迭代的描述,请参阅下文。 |
| 用户故事 - 冲刺 | 用户故事经常与冲刺相关联(参见下文对冲刺的描述)。理想情况下,用户故事应该始终与冲刺相关联。 |
| 用户故事 - 组 | 用户故事可以分组。 |
组

组是组织用户故事的任意概念。然而,组织是有用的。例如,我们可能希望查看与特定屏幕或特定规则集相关的所有用户故事。组的目的是允许您将许多实体组织在一个单一的伞下——例如,所有与客户端和服务器之间的传输层开发相关的任务是什么。
强调实体之间的关系,这里没有规则——实体可以属于任意数量的组。它只是一个允许您组织信息的机制。我发现需要这个是因为,在 ROP IDE 中,我会有很多任务,但当我真正想要的是能够对任务进行分组以便我能专注于一组特定的行为、屏幕等时,我会迷失在噪音中。
关联
| 用户故事 - 组 | 用户故事可以分组。 |
| 需求 - 组 | 需求可以分组。有关需求的描述,请参阅下文。 |
| 规范 - 组 | 规范可以分组。有关规范的描述,请参阅下文。 |
| 任务 - 组 | 任务可以分组。有关任务的描述,请参阅下文。 |
| 测试 - 组 | 测试可以属于一个组,例如,所有与离线事务管理相关的测试。有关测试的描述,请参阅下文。 |
| 缺陷 - 组 | 缺陷可以分组。有关缺陷的描述,请参阅下文。 |
需求

需求定义了用户故事的一些细粒度细节。这可能涉及性能问题(响应时间或并发用户数或每秒事务数或冗余)、数据管理问题(处理脏数据、自动客户端同步、离线使用等)、安全性、规则等等。需求实体应将用户故事叙述分解为单行项目,以揭示用户故事中“隐藏”的假设和含义。有时,如果用户故事足够详细,它听起来就像一个需求。一个例子是“日期字段应默认为当前日期”。如果发生这种情况,那么详细的用户故事是否应在需求中描述或在需求中重复就变得有点武断了。
关联
| 需求 - 项目 | 需求可以与项目相关联。这应被视为用户故事尚不存在时的占位符。 |
| 需求 - 用户故事 | 需求来源于用户故事。 |
| 需求 - 需求 | 我不太常遇到这种情况,但其思想是需求可以以同级关联(一个需求引用另一个需求)或主/从关系与D其他需求相关联。 |
规范

规范详细说明了用户故事、任务或需求将如何实现。规范从技术、算法等方面描述实际的实现方法。例如,压缩视频的需求可能具有特定算法的规范。相同的规范可能与实现该算法的任务相关联,或者,如果使用第三方库,则与该库的接口相关联。然而,规范也可以是文档,例如架构、通信协议、Web 服务等。
理解需求和规范之间的区别很重要。需求描述“什么”,而规范描述“如何”。例如,在 GAPMA 中,我要求屏幕需要支持 DevExpress 和基于 .NET 的控件。对此的规范是屏幕将以 XML 实现并使用 MyXaml 实例化。后者不是一个需求——它仅仅指定了如何满足该需求。
这里最好的做法是问自己两个问题
- 用户故事产生了哪些具体需求(这是一个需求)
- 需求将如何实现(这是一个规范)
关联
| 规范 - 项目 | 规范可以与项目相关联。不建议这样做,但可以用作以后确定规范应与哪个实体相关联的占位符。 |
| 规范 - 用户故事 | 规范可以与用户故事相关联。例如,用户可以指定应使用哪种数据库技术,例如 Oracle。 |
| 规范 - 需求 | 规范通常与需求相关联。给定一个需求,应该使用哪些技术、工具等来满足该需求? |
| 规范 - 规范 | 与需求一样,规范可以引用另一个规范,或者作为主规范的细节。 |
任务

任务定义了需要完成的工作。
关联
| 任务 - 项目 | 任务可以分配给项目。这是我发现最常用的通用关联,当我发现需要完成某项工作但没有用户故事、缺陷或需求实体可以与之关联时,它很有用。任务也可以是描述性的,例如“从存储库中检出代码?”或“构建项目”或“运行单元测试”。是的,这些也可以作为单独文档的候选项,但我们可以灵活! |
| 任务 - 用户故事 | 任务可以来源于用户故事。给定一个叙述,需要完成的工作是什么?这不一定意味着编程工作。任务可以是各种各样的事情:从戴夫那里获取一些屏幕截图,获取有关用户故事的更多细节,编写一些文档,研究现有技术,考虑为此方法申请专利。 |
| 任务 - 需求 | 任务可以与需求相关联。给定需求,实现该需求所需的任务是什么?通常,任务将与需求而不是用户故事相关联,但由于这些关系都是任意的(通常由项目规模决定),您可能会觉得将任务直接与用户故事关联符合您的需求。 |
| 任务 - 任务(子任务) | 任务可以有子任务,进一步细化待完成工作的描述。 |
| 任务 - 任务(依赖) | 依赖项是什么?这些通常涉及一个任务的完成才能继续另一个任务。依赖项也可以更抽象——在一个任务依赖于该规范完成之前,依赖于一个部门提供数据库架构(一个任务)。依赖项对于任务排序是必需的。我们通常以特定的顺序执行任务,这意味着任务之间存在依赖项。我们不提供任务实体中的“序列”属性,而是通过实际描述依赖项来提供更多含义。 |
| 任务 - 迭代 | 任务可以属于一个迭代。有关迭代的描述,请参阅下文。 |
| 任务 - 冲刺 | 任务与冲刺相关联。理想情况下,任务应始终与冲刺相关联,无论是直接还是通过任务与用户故事的关联间接关联。 |
测试

我们如何测试项目的组件?
关联
| 测试 - 项目 | 可能不是一个好主意,因为您不是针对特定事物进行测试,但也许在会议中有人问“嘿,我们真的测试过通过 14400 波特调制解调器进行数据传输吗?”时,这是一个有用的占位符。 |
| 测试 - 用户故事 | 我们可能希望为用户故事编写一个测试。这是“验收测试”概念最适用之处,因为验收测试将描述一系列步骤,以证明满足用户故事中的要求。 |
| 测试 - 需求(针对需求进行测试) | 可以编写一个测试来确定需求是否得到满足。当我们启动屏幕时,日期字段是否填充了今天的日期?国家/地区选择列表是否根据某些操作系统注册信息自动选择用户的国家/地区? |
| 测试 - 需求(测试有需求) | 执行测试所需的设置要求是什么?这里对需求实体有不同的含义,基于关系用法(我将在本文后面讨论这一点)。 |
| 测试 - 任务 | 与任务相关的测试可以是验收测试或单元测试,或两者兼而有之,或另有其他。这很大程度上取决于任务。 |
| 测试 - 缺陷 | 与缺陷相关的测试通常应描述缺陷修复是如何测试的。 |
| 测试 - 测试(主/从) | 测试可以是递归的,意思就是“测试飞机是否飞行”可能需要进行大量子测试,飞行员才能以高速将飞机开上跑道。 |
| 测试 - 测试(依赖) | 描述测试之间的依赖关系通常很有用。例如,测试事务是否可以发布取决于连接到服务器的测试是否成功。我不喜欢看到一百个失败的单元测试只是因为一个所有其他测试都依赖的测试失败了。这会造成不必要的恐慌。 |
| 测试 - 任务(依赖) | 这是一个有趣的概念——我们有没有一个测试是依赖于任务完成的?意思是,如果任务没有完成,那么显然还没有什么可测试的。只是一个想法。 |
缺陷

缺陷可能是应用程序的严重故障、缺失功能、功能不正确等等。正如我在之前的文章中提到的,一个人的缺陷可能在另一个人看来是“按设计工作”。
关联
| 缺陷 - 项目 | 在测试中,最常出现的缺陷与任何特定的用户故事或任务完全无关。我发现使用 ROP IDE 时经常出现这种情况——“嘿,看看那个奇怪的行为!”因此,至少,缺陷是附加到项目本身的。 |
| 缺陷 - 用户故事 | 在测试中,用户可能会报告特定用户故事的缺陷,我们希望捕获这些缺陷。测试人员很可能不会报告任务的缺陷,因为内部任务往往是隐藏的。但是,如果他/她正在根据用户故事测试特定实现,并且发生了意外情况,那么这就是用户将关联缺陷(并且以后会想重新测试)的地方。 |
| 缺陷 - 任务 | 缺陷可以与任务相关联,通常是已完成的任务。 |
| 缺陷 - 测试 | 测试也可能存在缺陷! |
| 缺陷 - 组 | 缺陷可以分组在一起。例如,可能有一组缺陷都与特定的 UI 元素相关。 |
解决方案

多年以后,您可能想知道一个任务实际上是如何实现的(尤其是在没有需求或规范的情况下!)。然而,主要地,解决方案描述了如何纠正与缺陷相关的任务(或者如果它没有被纠正,也许它被推迟到另一个迭代/发布)。
关联
| 解决方案 - 任务 | 任务当然不都是“修复这个”。它可能是“实现这个功能”,为此记录实现是如何解决的可能很有用。 |
| 解决方案 - 缺陷 | 在这种情况下,解决方案文档说明了如何修复缺陷(或者如果不需要修复,也许程序就是这样设计的)。 |
迭代

迭代主要由用户故事组成。它回答了这样一个问题:我们希望在下一个“发布”中实现哪些用户故事项的集合,其中发布的概念可以是内部的或外部的(交付给用户)。出于规划目的,迭代可能只是一个占位符。迭代本质上是一些任意的计划(或未计划)里程碑。它可以代表付款所依赖的交付,或者它可以代表某些功能的完成。迭代不应与组混淆,即使迭代是一种用户故事和/或任务的分组。组只是一种集合,而迭代包含完成的概念。
关联
| 迭代 - 项目 | 迭代属于一个项目。 |
冲刺

冲刺描述了在短时间内(通常是两周)要完成的用户故事和/或任务。冲刺体现了完成的概念。随着冲刺的完成,项目“速度”可以通过将冲刺中的任务与任务数量、完成任务的实际时间与估计时间等相关联来衡量。
关联
| 冲刺 - 项目 | 冲刺属于一个项目。 |
| 冲刺 - 组 | 冲刺可以以某种任意方式分组。这应该与迭代不同。例如,您可能将几个冲刺都与一个实现相关联,例如通信层。 |
进度

“完成”意味着什么?
“完成”标志的一个问题是,虽然勾选时它的含义很明确,但未勾选时它的含义却不明确。例如,未勾选的“完成”框可能意味着任务尚未开始工作,或者工作已开始但尚未完成。或者它已经完成但没有人将其标记为已完成(也许它正在测试中,虽然任务本身已完成,但工作流中的其他要求尚未完成)。我们想要的是对象实际处于什么状态的清晰度。对于任务尤其如此——从 看板 的角度来看,我们希望能够看到哪些任务未分配,哪些已分配(正在进行中),以及哪些已完成。我将稍微修改这个概念
- 未准备好
- 未分配
- 已分配但工作未开始
- 已分配且工作进行中
- 工作已完成
如您所见,“完成”概念现在有五种状态!因此,为了提高清晰度,我们用一个更精确的概念取代了“完整性”的概念:进度。
为什么是单独的实体?
对于进度实体(以及下面描述的审查和批准实体),有人可能会说,为什么它们不只是所需实体中的标志呢?这是一个合理的问题,答案是进度实体与其他实体处于 1:1 关系中,因此从用户的角度来看,关系始终被创建,并且字段(在本例中是进度状态)始终作为与进度相关联的实体中的字段呈现。也有可能您希望进度实体除了进度状态之外还有其他字段。分配给工作的人员的姓名可能是一个属性,但正如我们将看到的,这实际上是通过与姓名实体的关联来实现的。
关联(右侧的所有实体都可以有一个与之关联的进度实体)
| 进度 - 项目 |
| 进度 - 用户故事 |
| 进度 - 任务 |
| 进度 - 冲刺 |
| 进度 - 迭代 |
| 进度 - 文档 |
| 进度 - 审查 |
| 进度 - 批准 |
请注意进度与审查和批准实体之间的关系,下面将对此进行描述。我们显然也希望跟踪某事物在审查和批准过程中的位置!
审查

有时我真的很讨厌团队合作,因为代码质量差异很大。正式的审查过程是件好事,在快节奏(即混乱)的敏捷环境中,退后一步审查已完成的工作是件好事。审查有接受和拒绝标志,以及审查员可以添加的描述,通常是实体被拒绝的原因。因此,缺陷实体也有一个审查关联。审查实体始终与其他实体处于 1:1 关系中。
审查实体可以有三种状态
- 不适用(对于不完整的批准)
- 已批准
- 已拒绝
关联(右侧的所有实体都可以有一个与之关联的进度实体)
| 审查 - 项目 |
| 审查 - 用户故事 |
| 审查 - 任务 |
| 审查 - 需求 |
| 审查 - 规范 |
| 审查 - 冲刺 |
| 审查 - 迭代 |
| 审查 - 文档 |
批准

审查和接受用户故事、缺陷或任务的人员可能与最终批准的人员不同(如果审查和批准由委员会完成,上帝保佑)。例如,批准可能由客户拥有。批准始终与其关联实体保持 1:1 关系。
与审查实体一样,批准实体可以具有相同的状态
- 不适用(对于不完整的批准)
- 已批准
- 已拒绝
显然,与审查有关联的实体也应该与批准有关联
关联
| 批准 - 项目 |
| 批准 - 用户故事 |
| 批准 - 任务 |
| 批准 - 需求 |
| 批准 - 规范 |
| 批准 - 冲刺 |
| 批准 - 迭代 |
| 批准 - 文档 |
笔记
注释实体是内部文本(与下面的文档相反)。注释可以与所有实体关联,呈 1:多关系(实体 - 注释)——我们可以为每个实体实例编写多条注释——甚至可以与自身关联。谁知道呢,您可能希望能够以分层方式进行注释(笔记)。
关联:所有实体。
文档
文档实体引用外部文档:文本、图像、视频、音频、网页、数据库等。文档可能是一个缺陷的屏幕截图或视频,或现有或竞争产品中的现有实现,或对现有专利的一些引用,会议的录音,我们需要接口的外部数据库示例,第三方规范或架构等。只是想法。像注释一样,文档实体可以与所有实体关联,并以 1:多关系(实体 - 文档)存在。
关联:所有实体。
人员

人员可以描述许多重要的关联。对于一个用户故事,谁“拥有”这个故事——即,谁是提出这个故事的人,我们可能会在有问题时回到他/她那里?谁是分配给用户故事以创建任务的人?从工作流的角度来看(见下文),谁是审查用户故事的人,这可能与最终批准用户故事的人不同。本质上,一个人可以以某种类型的关系与所有其他实体关联,无论是任务的受让人,监督冲刺的人,文档的作者等等。唯一无法创建用例的实体是进度实体,因为人员和进度都将与同一个父实体关联。
“人”也不必描述一个人——它也可以是一个人群。例如,用参与者来描述一个项目:您有客户以及客户现场负责项目不同方面(用户故事实例)的各种人员。项目中所有初级程序员是谁?所有高级程序员是谁?UI 设计师是谁?测试人员是谁?您可以看到“组”实体与“人”实体相关联时很有用。
您可能会认为将某个事物(例如任务)分配给一群人(例如委员会)会很有用。就 GAPMA 而言,我的概念是最终由一个人完成工作。这在审查/批准层面可能不成立。如果您希望每个人都聚集在一起在项目完成时唱“哈利路亚”,这可能不成立。因为 ROP 是灵活的,您当然可以根据自己的意愿创建自己的关系和新实体!
Types
我建议为人们在项目中担任的各种角色创建关系类型。一些建议
- Owner
- 设计器
- 潜在客户
- 管理器
- 审阅者
- 开发版
- 测试员
关联(描述仅为示例)
| 人员 - 项目 | 将人员与项目关联。项目中的所有参与者是谁? |
| 人员 - 用户故事 | 用户故事的所有利益相关者、审阅者等是谁? |
| 人员 - 任务 | 任务分配给谁? |
| 人员 - 缺陷 | 谁报告了缺陷? |
| 人员 - 解决方案 | 谁解决了问题? |
| 人员 - 迭代 | 谁负责监督迭代? |
| 人员 - 冲刺 | 谁是冲刺的负责人? |
| 人员 - 组 | 有哪些不同的人员组? |
| 人员 - 需求 | 谁是需求的作者?谁负责维护它? |
| 人员 - 规范 | 谁是规范的作者? |
| 人员 - 测试 | 有没有专门的人员拥有运行测试的设备? |
| 人员 - 审查 | 谁是审阅者? |
| 人员 - 批准 | 谁是批准者? |
| 人员 - 备注 | 谁是备注的作者? |
| 人员 - 文档 | 谁是文档的作者? |
| 人员 - 工具 | 谁编写了该工具?谁维护它? |
工具

在我的上一篇文章中,我写道,描述特定任务或测试所使用的工具通常很有用。因此,我们有一个工具实体。是的,这可以记录在笔记或文档中,但将实体正式化可以促使人们思考它。
关联
| 工具 - 项目 | 描述用于创建和维护项目的工具。 |
| 工具 - 用户故事 | 描述展示用户故事可能需要的工具。 |
| 工具 - 任务 | 任务可能需要特定的工具来完成。 |
| 工具 - 测试 | 测试可能需要特定的工具(除了单元测试工具) |
| 工具 - 文档 | 我喜欢能够生成有用文档的工具,无论是图表还是文本。例如,我希望有一个工具可以为所有这些实体和关系生成文本。 |
| 工具 - 组 | 您可能希望对工具进行分组:开发工具、测试工具、文档工具等。 |
术语

在实际使用中,我发现用户故事中充满了用户工作领域特有的术语。更复杂的是,我经常发现同一个术语在不同的人、部门、领域等处具有不同的含义。我发现拥有一个与项目相关的术语表及其含义非常有用。
关联
| 术语 - 项目 | 描述项目中使用的术语。 |
| 术语 - 用户故事 | 可以为方便起见创建此关联,以便能够立即引用特定用户故事中使用的术语。 |
| 术语 - 需求 | 需求通常使用我们可能希望建立直接关联的术语。 |
| 术语 - 规范 | 规范通常使用我们可能希望建立直接关联的术语。 |
| 术语 - 工具 | 工具也是如此。 |
| 术语 - 组 | 术语分组通常很有用。 |
面向关系编程实践
另一个必要的正式化是定义使用 ROP 架构的最佳实践。以下是我目前提出的一些最佳实践。
重载属性含义和重复属性
当我们为实体分配属性时,请考虑该属性是否逻辑上描述了一个概念,如果它在单独的实体中指定,则该概念实际上可以具有特定的上下文含义。还要考虑当一个属性在多个实体中重复时,最好将其提升为一个实体。例如,如果 Task 有一个 Completed 属性,并且没有其他实体具有此属性,那么用户可能被迫重载此属性的含义。一个例子是,用户可能会选择使用此标志来指示 Task -> Resolution -> Test -> Review -> Approve 的整个工作流已“完成”,仅仅因为架构设计者没有提供在其他实体中指定“完成”的能力。我们多久因为预期概念不符合我们的实际需求而精神上为字段分配了一个新含义?因此,实践是
- 在与其他实体的关系上下文中提供含义
理想情况下,实体的逻辑含义应简洁但抽象,而物理含义,当与另一个实体相关联时,应同样简洁,但在关系的上下文中具体。
实体属性应该是基本类型
实体的属性应从属性与实体的关系角度考虑,这隐含在实体具有属性的事实中。例如,Name 和 Person 之间的关系可以提示您,也许 Name 属性实际上应该是一个实体,因为 Name 不是基本数据类型。一个更微妙的例子是 Task 的 Completed 属性。它微妙是因为我们可能希望为状态概念附加额外的属性:状态何时发生,以及由谁发生?
因此,在为实体分配属性时,请考虑
- 此属性是否真的是一个基本数据类型,永远不会拥有自己的任何属性?
- 此属性是否描述状态,而状态本身可以具有附加属性?
- 使用关于重载含义和重复属性的指导来确定该属性(即使它是基本数据类型)是否应该是一个单独的实体。
如果您对上述任何一个问题回答“是”,那么建议的做法是将该属性创建为一个实体,并定义所有允许的实体关系,这些关系当然会随着应用程序需求的变化而扩展。因此,“完成”的概念是在一个单独的实体中处理的。
我希望如何查询数据?
另一个指导是您可能希望如何查询结果数据集。例如,您是只希望查询已完成的任务,还是用户会对各种不同实体的完成情况感兴趣?您是否想知道一个缺陷是否已完成?经理是否想知道实施是否已审查?技术负责人是否想知道哪些任务已完成并等待他/她的审查?所有这些都检查各种实体的完成状态。值得探索数据可能被查询的方式,因为这为如何创建实体属性以及属性是否应该提升为实体提供了指导。如果同一个属性,在其逻辑含义上,将在不同的物理表示中重复使用,这些表示仅在物理含义上不同,但在逻辑含义上相同,那么这表明该属性应该是一个单独的实体。
创建有意义的关系
一个关键概念
大多数 GAPMA 关系只是为了描述层次结构而定义的。因此,GAPMA 并不是 ROP 强大功能的最佳示例。我们已经习惯于从外键的角度思考关系,这本质上描述了一个层次结构。由于每个关系都被强行塞入外键的概念,因此通常会在关系本身中携带的信息在外键字段中表达。例如,一个人可能有一个 MarriedToID 字段。但这非常有限,因为它无法捕捉多次婚姻以及更普遍的,一个人可以与另一个人建立的各种伙伴关系。因此,我们应该开始将关系视为本身具有意义。ROP 的关键概念之一是,这种意义保留在关系中,而不是在表的外键字段中或(稍微好一点)特定的关联表中表达。
除了主要静态的层次关系之外,我们还有实体之间描述事件发生的关系(出生、犯罪、死亡等)。事件是在特定时间点发生的事情。还有一些关系具有开始和潜在的结束时间(即婚姻、居住、工作等)。这些类型的关系在技术上描述了两个事件(即婚姻和离婚、就业和终止等),但将物理概念抽象为开始和结束点的单一组合是有用的,其中开始和结束点的含义由关系的上下文决定。
因此,为了理解关系的含义,确定关系属于以下三种形式中的哪一种很有用
- 关联层次信息(在 GAPMA 中我们看到,这往往是静态的)
- 由于静态外部事件而关联实体
- 具有潜在关闭(完成)且性质通常更动态的关联
这是一个涉及所有这三种关系形式的例子:一项对失踪钱财的调查导致发现儿子一直在偷父亲钱包里的钱。这里有三种关系形式
- 层次:父子关系
- 外部事件:特定日期和时间发生的犯罪(发现钱财失踪),以关系“人(受害者)- 犯罪(偷窃钱财)”表示
- 暂时性事件:调查员调查犯罪。这是一种“人(调查员)- 犯罪”关系,具有开始和结束日期/时间。
关系
在上一篇文章中,我基本上忽略了我在开始本系列时最初写过的关系的关键概念。现在是时候重新审视这些概念并更正式地处理它们了!不幸的是,GAPMA 并不是最好的例子,因为 GAPMA 中的关系往往是静态的,而不是像执法数据库那样,关系非常动态。尽管如此,我仍将努力从 GAPMA 中提取一些有价值的关系方面。
在上一节中,我描述了关系的三种形式
- 用于层次结构目的的关联
- 事件结果的关联
- 描述暂时性关系的关联
现在我们将研究为这三种形式提供有用含义的属性。
有意义的关系属性
所有关系至少有两个共同属性
- 关系创建时间
- 关系创建者
这很明显是与“关系实例”相关的有用信息。不那么明显的是,关系中的实体类型通常是关系类型的指示器:层次、事件或暂时性。这并非硬性规定——人-人关系可能是层次的(父母、子女、朋友等),但也可能是事件(谋杀)或暂时性(1 月 1 日结为朋友,1 月 2 日解除朋友关系)。
层次关系属性
层次关系隐含在任意两个实体之间的关系中。在层次关系中,描述关系所需的唯一属性可以通过实体类型确定:缺陷“与”项目“关联”,用户故事“由”任务“组成”,任务“构成”迭代。因此,实体类型的关系可以提供超出“拥有”和“是”的更具体含义。这在 ROP 中通过创建两个实体类型之间的关系来表达。
基于事件的关系
基于事件的关系,例如描述出生、死亡、犯罪现场等的“人员-地点”关系,具有日期/时间“发生于”属性和涉及“实体实例”的“关系实例”的类型描述符属性。这与上面描述的层次关系属性形成对比,后者是涉及“实体类型”的“关系类型”的描述符。我们通常希望根据关系中涉及的“实体类型”提供允许的类型描述符的选择列表。
事件的日期/时间“不应与”关系创建的日期/时间“混淆”。
暂时性关系
这种关系没有“发生于”属性,而是有“开始日期/时间”和“结束日期/时间”属性。与基于事件的关系类似,它有一个类型描述符,我们应该有一个选择列表,但这些都实现为描述符对,例如“雇用 - 终止”、“迁入 - 迁出”、“结婚 - 离婚”、“结婚 - 丧偶”等等。
GAPMA 关系
我们可以在 GAPMA 中看到这三种关系类型
- 与项目关联的用户故事是层次化的;
- 任务-缺陷关系是暂时性的,希望任务有开始和完成时间;
- 项目与缺陷之间的关系可以认为是基于事件的,因为缺陷“发生于”特定时间点。更具体地说,在这种情况下,通用的“发生于”值可以是“报告于”描述。
然而,这里存在日期/时间属性最佳位置的歧义,我将在下面详细探讨。
基于事件的关系和日期/时间属性
ROP 中容易混淆的地方之一是日期/时间属性应该放在哪里。例如,缺陷实体拥有“报告于”日期/时间属性似乎是合理的,但是如果您想要一个“报告于”和“发现于”日期/时间怎么办?这是一个有点牵强的例子,但对于说明目的仍然有用。更具体的问题是,在描述出生地点的人员-地点关系中,“出生于”属性应该放在人员实体还是关系中?
这些问题值得深思,因此,让我们用两个不同的例子来探讨这些问题。
示例 1:“出生日期”属性
在第一个选项中,Person 实体没有“出生日期”属性。在某个时候,我们创建了一个 Person-Location 关系类型,其中一个可用于描述此关系的“事件”类型是“出生地”。那么,使用事件关系的“发生于”属性来表示出生日期似乎是合理的。但在显示 Person 记录时,如果我们查看基于事件的关系实例并自动将“出生日期”字段添加到 Person “显示”记录(如果存在“出生地”关系描述符),这也似乎是合理的。
在第二个选项中,Person 实体已创建了“出生日期”属性。同样,在某个时候,我们创建了一个 Person-Location 关系类型,其描述符为“出生地”。在这种情况下,当我们查看 Person-Location 关系时,用 Person “出生日期”属性的值填充“发生于”字段似乎是合理的。
在这种特定情况下,使用人-地点关系实例来填充“出生日期”属性似乎很荒谬——毕竟,这是人与他/她的出生日期之间的 1:1“关系”。但是,如果我们要检查描述“出生地”的人-地点关系实例,将人的“出生日期”属性与关系的“发生于”属性关联起来是有意义的,因此我们可以将出生日期作为关系数据的一部分显示。
这是一个关键点:能够将事件关系与关系中某个实体的字段关联起来。最佳实践是
- 事件(日期/时间)是否“总是”存在(即使未知,我们也知道它存在)于实体中?
- 属性的抽象是否是原始数据类型?如果是,它作为实体的属性存在而不是在单独的实体中似乎是合理的。
- 抽象数据类型是否描述了一个结构,它不仅仅是原始数据类型的分解? (DateTime 可以分解为 Date 和 Time,但这不会增加任何额外的价值)
顺便提一下,如果最初的需求没有要求 Person 实体中包含“出生日期”字段,我们可以稍后通过简单地将属性添加到 Person 实体来添加它。UI 将自动显示此新字段——无需通过 ROP IDE 提供的自动 UI 生成来重新制作它们。
反之,将“出生地”属性表示为“人物-地点”关系将是一种最佳实践,原因如下
- 出生地不是时间量
- 出生地可能包含许多描述它的字段:城市、州、地理编码等。
- 出生地可以抽象为地点实体,而“出生日期”只能抽象为日期/时间,其本身就是原始数据类型。
示例 2:“报告犯罪日期”属性
这里我们有一个不总是存在的属性。一个人可能一生中从未报告过犯罪。此外,该属性的使用取决于关系(人员-犯罪)的存在。在这种情况下,关系类型(人员-犯罪)的“发生于”属性,其类型描述符为“报告”(而不是,例如,“受害者”或“施暴者”,它们不是事件关系而是层次关系),可以用文本“报告犯罪日期”来描述。这里的最佳实践是
- 事件(日期/时间)是可选的吗——它不总是存在吗?
- 它是否仅在创建事件关系时才存在?
- 关系可以是 1:多,而不是“总是”1:1 吗?
这类关系通常是 1 对多:一个人可能报告过许多罪行(一个人没有多个出生日期,除非使用别名,这应该明确它们是用别名实体描述的)。
暂时性关系
暂时性关系也有所不同——它们涉及“已创建”的实体,在这些实体中建立了新的关系。例如,调查员(一个人实体实例)将有一个犯罪调查的开始和结束日期。与缺陷相关的任务将有一个“开始工作日期”和“结束工作日期”范围。
有人可能会争辩说,任务应该内在具有“开始工作于”和“结束工作于”的属性。我将提出反驳意见,即任务只有与任务的原因(被分配到冲刺、缺陷、迭代等)相关时才有意义。因此,工作的开始/结束日期对这两个实体都有意义(这在冲刺或缺陷实体中最为明显)。所以,这里的最佳实践是,问自己:
- 这种关系的开始和结束日期对关系中涉及的两个实体都有意义吗?
- 当我们查询数据时,从所有关联子实体的开始/结束日期(换句话说,从父实体的角度看每个临时关系的生命周期)的角度来查看父实体是否有用?
如果任何实体所涉及的关系对这些问题有一个“是”的回答,那么很可能使用临时关系的属性而不是在实体中创建特定属性是有意义的。对于查询,我们可以绘制与冲刺实体有临时关系的所有实体的开始和结束日期,从而轻松可视化工作高峰,哪些子实体花费的时间最短,哪些最长等等。换句话说,我们可以轻松地从父实体的角度报告关系的生命周期。
关系类型和实例属性
从上述讨论(可以称为用户故事)中,我们可以推断出定义关系类型和关系实例所需的一小部分属性。我们已经描述过所有关系实例至少有两个属性:
- 创建于
- 创建者
这些实际上可以在关系实例创建时自动填充。我们现在可以描述关系类型和关系实例的其他属性。
关系类型属性
关系类型应包含一个描述符,说明其类型是什么:
- 分层
- 事件
- 临时
分层关系类型
分层关系类型具有属性:
- 实体类型A到实体类型B的物理描述
- 实体类型B到实体类型A的物理描述
“是”和“有”是通用概念,但我们通常希望根据关系类型提供更具体的描述符。一个例子:

所有术语都与其他实体具有分层关系。
事件关系类型
对于事件关系类型,我们有额外的属性:
- 实体类型名称映射到日期/时间字段
- 实体属性类型名称映射到实体的日期/时间字段
这些仅填充实体的“始终存在”的日期时间字段。
GAPMA中事件关系的一个例子:

缺陷,除了一组缺陷外,都是基于事件的,其中“报告于”字段是事件日期/时间。我想不出一个好的事件描述符例子——也许你能想到。
临时关系类型
对于临时关系(见下文),我们有额外的属性:
- 基于类型描述符的逻辑“开始于”概念的物理描述。例如“结婚于”
- 基于类型描述符的逻辑“结束于”概念的物理描述。例如,“离婚于”
- 可选地,在关系实例化时选择的物理描述符对的列表,例如,“离婚于”、“丧偶于”、“分居于”。
示例

任务是临时的——它们有开始和结束。项目冲刺也是如此。请注意,在上面的截图中,“任务-任务”关系有一个描述符类型,我将其指定为“依赖”或“子任务”的下拉列表。
关系实例属性
以下描述了三种关系实例的实例属性。
分层关系实例
这些没有额外的实例属性。
事件关系实例
对于基于事件的关系实例,我们有额外的属性:
- “发生于”日期时间值,用于“关系创建时”——该属性并非总是存在
- 描述符实例
它通常从下拉列表中描述事件(出生、死亡、婚姻、事故等)。在GAPMA中,并没有特别的描述可以添加到像缺陷-项目关联这样的“事件”中——即使将这种关联描述为事件,除了在“报告于”的上下文中,也有些可疑。
临时关系实例
对于临时关系,我们有额外的属性:
- 开始于
- 结束于
实现
以下部分描述了我上面讨论的所有功能的实现。
- 事件关系属性
- 临时关系属性
- 默认值
- 连接1:1关联
支持关系创建于和创建者
在ROP模式中,RelationshipInstance实体分配了两个属性:“CreatedOn”(日期时间)和“CreatedByID”,引用用户。为了提供所需的行为,我们必须在ROP中实现一些新功能。
“Created On”属性
属性“CreatedOn”提出了为此属性(或任何属性,实际上)定义默认值的问题。
实现属性默认值
首先,我们向Attribute类添加DefaultValue属性
[Category("Options")]
[XmlAttribute()]
[Description("The default value assigned when an instance using this attribute is created.")]
public string DefaultValue { get; set; }
创建新行时分配默认值
现在,当我们创建实例(在模型中)时,我们可以分配默认值。这可以通过在DataSet创建时用两行代码完成,通过初始化DataColumn的DefaultValue属性
if (ropAttr.HasDefaultValue)
{
dc.DefaultValue = ropAttr.DefaultValue;
}
然而,对于日期和时间等字段,我们还添加了提供“宏”功能来解析默认值的能力,此外,对于日期/时间等字段,这需要在记录创建时解析,而不是在DataSet实例化时解析。如果默认值是宏(例如“@Now”),则上述代码将不起作用。因此,我们首先希望使DataColumn类更智能
public class DefaultValueResolverDataColumn : DataColumn
{
new public string DefaultValue { get; set; }
public DefaultValueResolverDataColumn(string name, Type colType)
: base(name, colType)
{
}
}
现在使用DefaultValueDataColumn列创建DataSet,其中我们初始化DefaultValue
ROPLib.Attribute ropAttr = Schema.Instance.GetAttribute(attr.Name);
dc = new DefaultValueDataColumn(attr.FieldNameOrName, dataTypeMap[ropAttr.DataType]);
if (attr.IsPrimaryKey)
{
primaryKey = dc;
dc.AutoIncrement = true;
}
dc.DefaultValue = ropAttr.DefaultValue;
然后我们拦截TableNewRow事件以自行分配默认值
dt.TableNewRow += new DataTableNewRowEventHandler(OnTableNewRow);
dataSet.Tables.Add(dt);
并且实现(这在宏评估方面确实是骨感的!)是
/// <summary>
/// Manually add default values when they are defined, and resolve macros.
/// </summary>
protected void OnTableNewRow(object sender, DataTableNewRowEventArgs e)
{
foreach (DefaultValueDataColumn dc in e.Row.Table.Columns)
{
if (!String.IsNullOrEmpty(dc.DefaultValue))
{
object val = dc.DefaultValue;
string strval = dc.DefaultValue;
// Macro? (hopefully no value will begin with '@' !
if (strval[0] == '@')
{
if (strval[1] != '@')
{
// If it does, we are required in the schema to define the value as "@@something"
val = GetMacroValue(strval);
}
else
{
// Get rid of the first "@"
val = strval.Substring(1);
}
}
e.Row[dc] = val;
}
}
}
/// <summary>
/// Resolves a macro name to its value.
/// </summary>
protected object GetMacroValue(string macro)
{
switch (macro.ToUpper())
{
case "@NOW":
return DateTime.Now;
}
throw new ApplicationException("The macro " + macro + " is not supported.");
}
结果是每当创建新记录时,我们的关系记录中都有一个日期/时间值
![]()
“创建者”属性:菜单、变量和支持代码
第二个问题,CreatedByID属性,提出了一个有趣的问题:模式正在引用应用程序实例数据而不是模型实例数据。换句话说,CreatedByID将引用Person实体中特定记录的ID,但是Person实例实体不存在于模型级别(像实体类型或实体实例),而是存在于应用程序数据级别。在RelationshipInstance类中,我们已经有了一个例子——EntityAID和EntityBID字段是应用程序实例实体的引用。这种管理在创建关系实例时编写代码的方式中是隐式的,例如
int parentID = (int)child["EntityID"];
int childID = (int)parent["EntityID"];
entityProvider.AssociateParentWithChild(childID, parentID);
关于“CreatedByID”,模型无法对人员ID所在的实体做任何假设(我们可以硬编码假设,但这不是一个好主意)。这意味着我们需要一个登录对话框,但同样,这是应用程序特定的。此外,我们需要能够指定某种“变量”来保存当前用户的ID值,该值在实例创建时指定为默认值。此变量的值在用户登录时在运行时确定。所以,我们将退后几步,以实现一个巨大的飞跃:
- 支持应用程序特定的UI
- 支持应用程序特定的菜单以调用这些UI
- 实现变量的概念
- 实现一些初始智能,从应用程序数据的选择列表中填充变量的值
- 将变量映射为列的默认值的宏
我创建了一个简单的概念,即可以通过应用程序指定的菜单结构调用应用程序特定的UI。菜单在运行时根据加载的数据集加载,并且表单(作为MyXaml文件)也在运行时实例化。
菜单实体所需的属性
首先,让我们在模式本身中创建菜单系统所需的一些属性

接下来,我们创建一个菜单实例实体

创建菜单 - 父菜单关系
以及ParentMenuID和ID之间的关系

我们现在可以定义一个简单的顶级菜单“应用程序”,它有一个名为“登录”的子菜单,用于加载表单“login.myxaml”

在运行时附加应用程序菜单
现在我们只需向ROP应用程序添加智能,使其在数据集中查找菜单实体,并在应用程序中动态实例化此菜单以及标准菜单项
/// <summary>
/// Removes any existing application-specific menus and creates
/// new ones based on the current dataset Menu tree hierarchy.
/// </summary>
protected void UpdateMenus()
{
RemoveCustomMenus();
DataSet dataSet = ((DataSetProvider)dsp).DataSet;
if (dataSet.Tables.Contains("Menu"))
{
DataTable dtMenu = dataSet.Tables["Menu"];
topLevelMenuItems = CreateMenu(dtMenu, DBNull.Value);
// Append top level menus.
foreach (ToolStripMenuItem tsmi in topLevelMenuItems)
{
menuStrip.Items.Add(tsmi);
}
}
}
protected List<ToolStripMenuItem> CreateMenu(DataTable dtMenu, object parentID)
{
List<ToolStripMenuItem> menuItems = new List<ToolStripMenuItem>();
var items = from item in dtMenu.AsEnumerable()
where item["ParentMenuID"].Equals(parentID)
select new
{
ID=item.Field<int>("ID"),
Name = item.Field<string>("Name"),
Form=item.Field<string>("Form"),
ParentID = item["ParentMenuID"],
};
foreach (var item in items)
{
ToolStripMenuItem tsmi = new ToolStripMenuItem(item.Name);
// Only add event handler if there is an associated form.
if (!String.IsNullOrEmpty(item.Form))
{
tsmi.Tag = item.Form;
tsmi.Click += new EventHandler(OnApplicationMenuClick);
}
menuItems.Add(tsmi);
// Recurse into children.
List<ToolStripMenuItem> childMenuItems = CreateMenu(dtMenu, item.ID);
// Idiotic implementation, where a MenuStrip has an Items
// collection and a ToolStripMenuItem has a DropDownItems collection.
// The designer of this should have considered
// a common interface with an Items collection!!!
foreach(ToolStripMenuItem childItem in childMenuItems)
{
tsmi.DropDownItems.Add(childItem);
}
}
return menuItems;
}
/// <summary>
/// Remove existing application-specific menus.
/// </summary>
protected void RemoveCustomMenus()
{
foreach (ToolStripMenuItem tsmi in topLevelMenuItems)
{
menuStrip.Items.Remove(tsmi);
}
}
/// <summary>
/// Handle the instantiation of the specified form in the application-specific menu.
/// </summary>
protected void OnApplicationMenuClick(object sender, EventArgs e)
{
ToolStripMenuItem tsmi = (ToolStripMenuItem)sender;
string formName = (string)tsmi.Tag;
Parser p = new Parser();
p.AddReference("App", this);
// We will probably want to provide some additional references,
// such as to the entity provider and/or dataset provider.
Form form = (Form)p.Instantiate(UI + formName, "*");
// And maybe a flag to indicate whether to load the form modal (dialog) or modeless.
form.ShowDialog();
}
最终结果是,我们可以添加应用程序特定的菜单,其中应用程序由数据集确定,因此应用程序特定的菜单包含在数据集中。

以声明方式执行此操作的优点是,任何应用程序特定的行为都可以通过引用插件模块,实例化必要的类,并在运行时将事件处理程序连接到该类来在XML中实例化。这是一种非常简单的方法来实现控制反转设计模式——您不需要庞大的IoC框架——我从不明白为什么我需要一个臃肿的IoC框架。
理想情况下,最好指定菜单插入的位置,但这可以留待以后的版本。
变量 - 存储应用程序值的地方
但我们还没完。如上所述,我们需要一个“变量”的概念。用户将选择他/她的用户名(我们可以将其扩展到登录,但目前没有必要)。需要发生几件事:
- 所选ID需要放入变量中
- 创建关系时,变量值需要用作默认值
- 模型编辑器需要足够智能,能够使用应用程序数据(而不是模型数据)来解析查找
- ROP属性类需要有额外的属性来支持此功能
- 需要有一些后端代码来支持创建登录UI,该UI将属性映射到查找控件(组合框),并将所选值填充到变量中。
变量实体和属性
首先,让我们向模式添加一个名为“Var”的实体,其中包含“Name”和“Value”属性
![]()
然后,在模型编辑器中,我们将为用户名添加一个条目(在本讨论的最后,您会发现它应该被称为“UsernameID”)

一个智能组合框,用于设置变量值
接下来,我们将创建一个智能控件,它知道如何将组合框中的选定值分配给此变量
public class SwfDataComboBox : ComboBox, ISupportInitialize
{
public DataSet DataSet { get; set; }
public string EntityName { get; set; }
public string VarName { get; set; }
new public string DisplayMember { get; set; }
protected bool initialized = false;
protected EntityProvider entityProvider;
public SwfDataComboBox()
{
SelectedValueChanged += new EventHandler(OnSelectedValueChanged);
}
public void BeginInit() { }
public void EndInit()
{
// Look ma, no error handling!
entityProvider = new EntityProvider(DataSet);
entityProvider.InitializeWithEntity(EntityName);
entityProvider.LoadTable();
base.DisplayMember = entityProvider.GetColumnNameMapping(DisplayMember);
DataSource = entityProvider.DataTable;
initialized = true;
// We assume that the ValueMember is an ID (the "ID" field).
Update();
}
protected void OnSelectedValueChanged(object sender, EventArgs e)
{
if (initialized)
{
UpdateVar();
}
}
protected void UpdateVar()
{
// Look ma, no error handling!
DataTable dtVar = DataSet.Tables["Var"];
dtVar.Select("Name='" + VarName + "'")[0]["Value"] = SelectedValue;
}
}
示例:添加几个人员实例
接下来,让我们在实体编辑器中添加几个用户,因为“Person”是应用程序模型中定义的实体

设置用户名的登录表单
现在我们只需要一个登录表单,为我们的自定义组合框提供必要的声明性信息,以连接应用程序实体实例和变量
<?xml version="1.0" encoding="utf-8" ?>
<MyXaml xmlns="System.Windows.Forms, System.Windows.Forms,
Version=2.0.0000.0, Culture=neutral, PublicKeyToken=b77a5c561934e089"
xmlns:ui="UI.DotNet, UI.DotNet"
xmlns:def="Definition"
xmlns:ref="Reference">
<Form Name="Login"
FormBorderStyle="FixedDialog"
AcceptButton="{btnOK}"
Text="Login"
ClientSize="400, 80"
StartPosition="CenterScreen">
<Controls>
<Label Location="10, 12" Size="70, 15" Text="Username:"/>
<ui:SwfDataComboBox Location="85, 10" Size="200, 20" DataSet="{DataSet}" EntityName="Person"
DisplayMember="Username" ValueMember="ID" VarName="Username"/>
<Button def:Name="btnOK" Location="300, 8" Size="80, 25" Text="OK" Click="{App.CloseForm}"/>
</Controls>
</Form>
</MyXaml>
现在,当我们选择一个用户时

变量“Username”被更新

有趣的是,选择被保存到我们的数据集中。这意味着我们可以自动选择上次使用的用户名。虽然有用(例如,配置信息、表单位置、上次使用的字段值等),但这种行为可能并非在所有情况下都可取。以后需要增强(你注意到我经常这么说)。但这里的想法是,我们对一些非常通用的功能有了一个良好的开端,我们可以在以后根据需要进行增强。
使用变量的值作为新行的默认值
接下来,当创建关系实例时,我们需要指定使用此变量的值,因此我们添加一个新的宏,@VAR
protected object GetMacroValue(string macro)
{
switch (macro.ToUpper().LeftOf('('))
{
case "@NOW":
return DateTime.Now;
case "@VAR":
{
string varName = macro.Between('(', ')');
object val = dataSet.Tables["Var"].Select("Name='" + varName + "'")[0]["Value"];
return val;
}
}
}
将变量指定为属性的默认值
我们将此值指定为CreatedByID属性的默认值

……现在,当我们创建一个关系实例时,日期和用户ID都被填充了
![]()
理想情况下,这个变量名应该是“UsernameID”,我会在演示数据集中修复它(老实说,我太懒了,不想重做所有的截图!)。然而,更改它不会影响代码——只会影响声明式代码。
映射应用程序记录
还有一个小细节:我们希望模型编辑器足够智能,能够显示用户的名称,而不是ID。事实上,这应该是一个下拉列表,以便“超级用户”可以更改此选择。
向属性类添加更多属性以支持映射
为此,我们必须回到模式的Attribute类,并添加一些额外的属性,以帮助模型编辑器弄清楚此字段表示哪个实体以及显示和值成员是什么
[Category("Application Lookup")]
[XmlAttribute()]
[Description("The name of the application entity that " +
"populates the list of allowable values for this field.")]
public string EntityName { get; set; }
[Category("Application Lookup")]
[XmlAttribute()]
[Description("The field that is displayed as the human-readable value.")]
public string DisplayMember { get; set; }
[Category("Application Lookup")]
[XmlAttribute()]
[Description("The field that represents the internal ID.")]
public string ValueMember { get; set; }
设置CreatedByID属性的新属性
CreatedByID属性的属性相应设置

向网格添加智能以在查找字段中使用映射的应用程序记录
然后相应地修改模型网格的创建(这在ModelEditor的InitializeColumns方法中)
// If the attribute associated with this column
// is an application lookup, then map this to a lookup control.
ROPLib.Attribute attr = Schema.Instance.GetAttribute(dc.ColumnName);
if (attr.HasApplicationLookup)
{
EntityProvider entityProvider = new EntityProvider(dataSet);
entityProvider.InitializeWithEntity(attr.EntityName);
entityProvider.LoadTable();
string displayMember = entityProvider.GetColumnNameMapping(attr.DisplayMember);
string valueMember = attr.ValueMember; // assumes "ID", not requiring a lookup.
DataTable dtSource = entityProvider.DataTable;
DataView dvSource = new DataView(dtSource);
dvSource.Sort = displayMember;
dgvModel.AddLookupColumn(dvSource, valueMember, displayMember, dc);
isLookup = true;
}
现在,当我们创建关系时,CreatedByID被设置为查找控件

我们就可以宣布成功了!
公开关系类型描述符
像“任务-任务”这样的实体关系有一个类型描述符——在GAPMA中,“任务-任务”可以是子任务或依赖关系类型。下拉列表应根据关系类型定义中指定的列表项进行筛选。我们希望公开此下拉列表,以便用户在创建关联时可以选择关系类型。此列表只有在关系类型定义了类型描述符时才能选择。对于此特定示例,我们将设置一个在模型中定义而不是在模式中定义的下拉列表。
首先,我们定义一个属性,“RelationshipTypeDescriptor”
![]()
具有以下属性

请注意,下拉列表是从*模型的*List实体确定的。不要问我为什么选择Name作为ValueMember。
这描述了关系类型,在GAPMA中,我们有以下关系类型:
- 任务-任务
- 子任务
- 依赖
- 测试-测试
- 子测试
- 依赖
- 测试-需求
- 针对需求的测试
- 具有需求的测试
接下来,我们将此属性添加到模式中定义的RelationshipType实体

然后,在模型编辑器中,我们编辑List实体并添加上面描述的三种关系描述类型

以及下拉列表项

最后,在我们的*模型*关系类型中,我们可以描述我们希望在用户创建这些特定关联时向他们公开的下拉列表

最后,我们需要在模式的RelationshipInstance实体中有一个RelationshipTypeDescriptorID属性,我们将为其分配用户选择的类型描述符。请注意,这里发生了一些非常隐秘的事情。最终分配的ID保证是唯一的,因为它是由ListItem记录的过滤列表确定的,这些记录是模型List实体管理的所有列表的所有项目。这是需要记住的事情,也解释了为什么我们不需要List ID和ListItem ID。因此,我们可以将属性直接关联到模型的ListItem实体

我们可以手动(在模型中)选择描述符类型ID

但这显然不是首选方法。请注意,列表未按关系描述符列表进行限定。这可能是我们以后可以添加的功能,但它涉及为网格中的每一行创建唯一的查找控件,因为下拉列表会根据类型描述符而改变,这是我目前不想解决的问题。
关联用户界面
我们现在需要在“关联”部分添加一个UI元素,允许用户为给定实例选择关系类型。首先,我们将在实体编辑器中添加一个用于选择此值的组合框
<Label Text="Rel. Type:" Location="360, 4" Size="60, 15"/>
<ComboBox def:Name="cbRelTypeDescr"
Location="420, 0" Size="100, 20"
ValueMember="ID" DisplayMember="Name"
Enabled="false"
SelectedIndexChanged="{EventHandlers.OnDescrTypeIDChanged}"/>
并在EventHandlers类中(命名不佳,因为这是处理实体编辑器事件的类!),我们自动初始化组合框字段
[MyXamlAutoInitialize]
ComboBox cbRelTypeDescr = null;
当选择“显示父数据”或“显示子数据”的关系类型时,我们可以调用该方法来填充描述符列表
protected void OnShowParentData(object sender, EventArgs eventArgs)
{
parentEntityTypeID = (int)cbParentEntities.SelectedValue;
associating = Associating.Parent;
ShowEntityInstances(parentEntityTypeID);
PopulateRelationshipTypeDescriptorList(entityTypeID, parentEntityTypeID);
}
protected void OnShowChildData(object sender, EventArgs eventArgs)
{
childEntityTypeID = (int)cbChildEntities.SelectedValue;
associating = Associating.Child;
ShowEntityInstances(childEntityTypeID);
PopulateRelationshipTypeDescriptorList(childEntityTypeID, entityTypeID);
}
这涉及到获取关系类型ID……
public int GetRelationshipTypeIDFromEntityTypeIDs(int entityATypeID, int entityBTypeID)
{
var id = from row in dataSet.Tables["RelationshipType"].AsEnumerable()
where (row.Field<int>("EntityATypeID") == entityATypeID) &&
(row.Field<int>("EntityBTypeID")==entityBTypeID)
select row.Field<int>("ID");
return (int)id.First();
}
……并查找是否存在关联的关系类型描述符列表,以用描述符项目填充组合框
protected void PopulateRelationshipTypeDescriptorList(int entityATypeID, int entityBTypeID)
{
int relType = entityProvider.GetRelationshipTypeIDFromEntityTypeIDs(entityATypeID, entityBTypeID);
string typeDescrListName = (from row in entityProvider.DataSet.Tables["RelationshipType"].AsEnumerable()
where row.Field<int>("ID") == relType
select row.Field<string>("RelationshipTypeDescriptor")).FirstOrDefault();
if (!String.IsNullOrEmpty(typeDescrListName))
{
int listID = (from row in entityProvider.DataSet.Tables["List"].AsEnumerable()
where row.Field<string>("Name") == typeDescrListName
select row.Field<int>("ID")).First();
var items = (from row in entityProvider.DataSet.Tables["ListItem"].AsEnumerable()
where row.Field<int>("ListID") == listID
orderby row.Field<int>("Ordinality")
select new { ID = row.Field<int>("ID"), IsDefault =
row.Field<bool?>("IsDefault"), Name=row.Field<string>("Name") }).ToList();
cbRelTypeDescr.DataSource = items;
var defaultItem = items.FirstOrDefault(t => t.IsDefault == true);
if (defaultItem != null)
{
cbRelTypeDescr.SelectedValue = defaultItem.ID;
}
cbRelTypeDescr.Enabled = true;
}
else
{
cbRelTypeDescr.SelectedValue = -1;
cbRelTypeDescr.Enabled = false;
}
}
现在,当我们选择一个具有类型描述符的关系关联时,我们得到一个由描述符类型列表定义的描述符下拉列表

然后,当建立关联时,我们“仅仅”分配所选关系类型的ID
protected void OnDescrTypeIDChanged(object sender, EventArgs args)
{
relTypeDescrID = cbRelTypeDescr.SelectedValue as int?;
}
和
...
row["RelationshipTypeDescriptorID"] = relTypeDescrID;
...
我们可以通过检查模型中的RelationshipInstance实体来查看结果
![]()
公开关系事件描述符
在GAPMA中,缺陷事件只有一个事件描述符,它就是“发生于”(如果你能想到其他,可以添加)。我们希望公开事件描述符选择列表,以便在创建关联时,我们可以指定关系事件描述符。此列表应可用于事件关系类型。
在我们的ROP模型中,我们添加一个名为EventDescriptorID的属性
![]()
此属性的下拉列表将来自*应用程序*数据,因此我们将此实体的查找映射到应用程序的实体

我们将此属性添加到模型的RelationshipInstance中

我们通过编辑应用程序模型中的EntityType集合来添加*应用程序*实体类型
![]()
并将属性“Name”关联到新创建的实体类型
![]()
最后,我们通过“用户 -> 编辑应用程序数据”菜单在我们的*应用程序*数据中添加“发生于”描述符

现在,当我们使用模型检查我们的关系实例时,我们观察到有一个“事件描述符”*模型*列,其下拉列表来源于*应用程序*数据

这说明了与关系类型描述符不同的实现,后者使用*模型数据*作为下拉列表,而不是*应用程序*数据。我没有关于哪种方法更好的具体指导,每种方法都有利弊。
- 链接到模型数据的优点:下拉列表位于模型中,因此由模型携带。
- 链接到应用程序数据的优点:下拉列表位于模型引用的数据中,因此应用程序必须实现引用的实体。
目前,我只是想说明这两种方法。
关联用户界面
与关系类型描述符一样,我希望此属性在应用程序实体表单的关联部分中公开。这实际上涉及在表单中硬编码此实体的知识。该过程与关系类型描述符非常相似。在MyXaml中,由于项目列表来自EventDescriptors列表,我们可以从该实体填充组合框
<dotnet:SwfDataComboBox
def:Name="cbEventDescr"
Location="420, 35"
Size="100, 20"
DataSet="{dataset}"
EntityName="EventDescriptors"
ValueMember="ID"
DisplayMember="Name"
Enabled="false"
SelectedIndexChanged="{EventHandlers.OnEventTypeChanged}"/>
这为“事件”关系(例如缺陷-项目)提供了一个下拉列表

我们可以通过检查模型中的关系实例来查看选择
![]()
公开“开始于”和“结束于”属性
目前,由于没有任何规则触发器,我们希望允许用户编辑临时关系类型的“开始于”和“结束于”属性。因此,至少我们需要一个仅列出临时关系并允许用户输入其中一个或两个值的UI。在更复杂的应用程序中,我们希望以更复杂的方式公开这些属性,甚至通过一些规则触发器自动它们,但这将留待以后处理。
“开始于”和“结束于”属性被添加到模型的属性列表中,并且数据类型为“DateTime”

然后将它们添加到模型的RelationshipInstance实体中
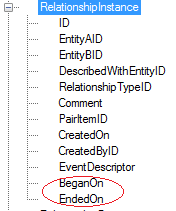
我们观察到RelationshipInstance实体现在具有这些属性

顺便说一句,在DevExpress网格中设置此属性的代码是
case "DATETIME":
editor = new RepositoryItemDateEdit();
((RepositoryItemDateEdit)editor).EditMask = "MM/dd/yyyy hh:mm tt";
((RepositoryItemDateEdit)editor).Mask.UseMaskAsDisplayFormat = true;
break;
关联用户界面
同样,这涉及到对这些属性的UI进行硬编码,这些属性的值在建立关联时分配。MyXaml部分
<Label Text="Began:" Location="350, 74" Size="70, 15"/>
<ui:DxDateTimeEdit def:Name="dtBeganOn" Location="420, 70" Size="100, 20" EditMask="MM/dd/yyyy hh:mm tt"/>
<Label Text="Ended:" Location="350, 109" Size="70, 15"/>
<ui:DxDateTimeEdit def:Name="dtEndedOn" Location="420, 105" Size="100, 20" EditMask="MM/dd/yyyy hh:mm tt"/>
这使我们能够为临时事件输入“开始于”和“结束于”日期时间信息(当不是临时事件时,控件被禁用并置空)

我们可以看到,当建立临时关系关联时,关系实例的BeganOn和EndedOn属性被设置
![]()
选择列表摘要
遗憾的是,我在选择列表方面制造了一些麻烦。有三种受支持的选择列表类型:
- 项目集合编码到元模型(左侧的树)中的列表,例如“关系类型”——分层、事件、临时——因此是模型(模式)。
- 项目集合包含在*模型的*List实体中的列表,例如关系类型描述符,因此是应用程序的序列化数据集。
- 项目集合包含在*应用程序*实体中的列表,因此是应用程序的序列化数据集。
我的借口是构建此应用程序的增量方法。显然,模式信息(例如关系类型)的“最佳实践”应属于模式。但是,如上所述,放置应用程序选择列表的位置尚不明确,尤其是当*模式*引用*模型*或*应用程序*实体时。这是一个令人困惑的实现混乱,我希望在某个时候解决它。
然而,目前,以下是指导原则:
- 静态(不依赖于应用程序)的类型描述可以放在模式列表集合中;
- 特定于应用程序但进一步定义*模型*类型(模式实例)的类型描述可以放在模型的列表集合中;
- 应用程序实体*实例*的描述与应用程序实体相关联。
希望这能说得通。
自动创建“与所有其他实体”关系
这适用于上面描述的注释和文档实体。我们希望自动为与所有其他实体存在关系的实体创建关系类型。这允许用户从这些其他实体中进行选择,而无需“超级用户”手动创建每个关系类型。在当前的实现中,这种“修复”发生在模型加载时。修复包括创建任何缺失的关系:
/// <summary>
/// Updates any missing relationship types for entity types designated as "associate to all."
/// These are always in the form: [assoc with all entity] -> parent entity.
/// (EntityA -> EntityB) as m:n hierarchical relationships
/// </summary>
protected void FixupRelationshipTypesOfAll()
{
DataSet dataSet = ((DataSetProvider)dsp).DataSet;
DataTable dtRelType = dataSet.Tables["RelationshipType"];
var assocToAll = from et in dataSet.Tables["EntityType"].AsEnumerable()
where et.Field<bool?>("AssociateWithAllEntities") == true
select new { Name = et.Field<string>("Name"), ID = et.Field<int>("ID") };
// Get all the entities to which this entity is NOT associated.
// For each "assoc to all" entity, get the list of entities where entityA
// != "assoc to all" entity && entityBID != entityID in RelationshipType
// meaning, where the entity is not in EntityB and also, "assoc to all"
// entity is not in Entity A. For these matches, we add entityA to the unassociated list.
foreach (var assocToAllEntity in assocToAll)
{
var unassoc = from et in dataSet.Tables["EntityType"].AsEnumerable()
where !(dataSet.Tables["RelationshipType"].AsEnumerable().Any(
rt => (rt.Field<int>("EntityATypeID") == assocToAllEntity.ID)
&& (rt.Field<int>("EntityBTypeID") == et.Field<int>("ID"))))
select new { Name = et.Field<string>("Name"), ID = et.Field<int>("ID") };
foreach (var unassocEntity in unassoc)
{
DataRow row = dtRelType.NewRow();
row["Name"] = assocToAllEntity.Name + " - " + unassocEntity.Name;
row["EntityATypeID"] = assocToAllEntity.ID;
row["EntityBTypeID"] = unassocEntity.ID;
row["Cardinality"] = "n:1";
row["RelationshipType"]="Hierarchical";
dtRelType.Rows.Add(row);
}
}
}
上述代码首先获取所有“关联到所有”实体,然后通过检查关系类型,为每个“关联到所有”实体查找未关联的实体。对于每个未关联的实体(关系类型缺失),显式创建关联作为多对一的分层关系类型。
查看上述代码,您可能想知道为什么我没有使用强类型DataSet。我认为这是一个有效的问题,并且可能在未来的某个版本中解决。
1:1关系
到目前为止,我们一直在实现的相当简单。1:1关系更有趣,因为它们具有期望的可视化和行为。这些包括:
- 当父实例创建时,自动创建与父实例具有1:1关系的子实体。
- 当新的实体类型被指定为与父实体具有1:1关系时,自动创建子实体。
- 自动为父实体添加1:1子实体属性。
- 管理最终由独立表处理的值的持久化。
在GAMPA中,有各种1:1关系。例如,实体Task和Progress之间存在1:1关系。我们将使用此特定实例,看看代码如何发展以支持上述需求。
应用程序查找列
首先,我们必须实现一个目前不存在的功能:应用程序数据中的查找字段。例如,进度状态是一个查找,但IDE目前在网格中显示一个简单的文本框编辑控件
![]()
这可不是我们想要的!问题出在这段代码中,它盲目地将所选实体的数据视图分配给网格,而不考虑查找控件。
protected void InitializeGrid()
{
BindingSource bs = new BindingSource();
bs.DataSource = entityProvider.DataView;
dgvData.DataSource = bs;
GridInfo.BindingSource = bs;
}
我们需要一些更智能的东西
...
InitializeGridData();
InitializeGridColumns();
}
protected void InitializeGridColumns()
{
dgvData.ClearColumns();
DataTable dt = entityProvider.DataTable;
int n = 0;
foreach (DataColumn dc in dt.Columns)
{
if (dc.ColumnMapping != MappingType.Hidden)
{
AttributeInfo attr = entityProvider.Attributes[n];
if (attr.PickListID == null)
{
dgvData.AddColumn(dc);
}
else
{
List<ItemList> items =
(from item in entityProvider.DataSet.Tables["ListItem"].AsEnumerable()
where item.Field<int>("ListID") == attr.PickListID
orderby item.Field<int>("Ordinality")
select new ItemList { ID = item.Field<int>("ID"),
Name = item.Field<string>("Name") }).ToList();
DataView dv = new DataView(items.ToDataTable());
dgvData.AddLookupColumn(dv, "ID", "Name", dc);
}
}
else
{
dgvData.AddColumn(dc);
}
++n;
}
}
这会产生一个漂亮的下拉框

自动包含1:1关系中所有实体的字段
首先,我们希望添加1:1关系中所有子实体的字段。字段顺序的确定是任意的。从可视化角度来看,我们还可以使用DevExpress的网格功能创建“分组列”以使字段组织对用户更清晰,但我会将其留待以后实现(也不是您在.NET网格控件中会看到的东西,因为它不具备此功能,我也不想尝试编码)。
实体字段目前由EntityProvider.cs中的PopulateEntityTypeAttributes方法填充
protected void PopulateEntityTypeAttributes(int entityTypeID)
{
// Get the AttributeType records for the EntityTypeAttributes
// records where the EntityTypeID = [entityTypeID]
attributes =
(from eta in dataSet.Tables["EntityTypeAttributes"].AsEnumerable()
where eta.Field<int>("EntityTypeID") == entityTypeID
join at in dataSet.Tables["AttributeType"].AsEnumerable()
on eta.Field<int>("AttributeTypeID") equals at.Field<int>("ID")
orderby eta.Field<int>("Ordinality")
select new AttributeInfo
{
ID=at.Field<int>("ID"),
EntityTypeID=eta.Field<int>("EntityTypeID"),
Name = at.Field<string>("Name"),
DataType = at.Field<string>("DataType"),
Length = at.Field<int>("Length"),
}).ToList();
}
我们希望合并所有与我们有1:1关系的实体的字段,这涉及到检查RelationshipType实例的Cardinality字段
protected void PopulateEntityTypeAttributes(int entityTypeID)
{
attributes = GetAttributes(entityTypeID, null);
MergeOneToOneEntityTypeFields(attributes, entityTypeID);
}
protected void MergeOneToOneEntityTypeFields(List<AttributeInfo> attributes, int entityTypeID)
{
var oneToOneEntityTypes =
from er in dataSet.Tables["RelationshipType"].AsEnumerable()
where (er.Field<int>("EntityBTypeID") ==
entityTypeID) && (er.Field<string>("Cardinality") == "1:1")
select er.Field<int>("EntityATypeID");
oneToOneEntityTypes.ForEach(t=>attributes.AddRange(GetAttributes(t, entityTypeID)));
}
protected List<AttributeInfo> GetAttributes(int entityTypeID, int? parentEntityTypeID=null)
{
// Get the AttributeType records for the EntityTypeAttributes
// records where the EntityTypeID = [entityTypeID]
List<AttributeInfo> attributes =
(from eta in dataSet.Tables["EntityTypeAttributes"].AsEnumerable()
where eta.Field<int>("EntityTypeID") == entityTypeID
join at in dataSet.Tables["AttributeType"].AsEnumerable()
on eta.Field<int>("AttributeTypeID") equals at.Field<int>("ID")
orderby eta.Field<int>("Ordinality")
select new AttributeInfo
{
ID=at.Field<int>("ID"),
EntityTypeID=eta.Field<int>("EntityTypeID"),
ParentEntityTypeID=parentEntityTypeID, // in a 1:1 relationship, the parent ID
Name = at.Field<string>("Name"),
DataType = at.Field<string>("DataType"),
Length = at.Field<int>("Length"),
PickListID = at.Field<int?>("PickListID"),
}).ToList();
return attributes;
}
请注意ParentEntityTypeID的赋值。此信息将用于持久化1:1实例值。
现在我们得到了所有与所选父级有1:1关系的子实体的附加列

创建新1:1实体和自动创建1:1关系时的修复
有三个考虑因素:
- 如果我们有现有的实体实例,并且我们添加了一些新的1:1关系实体类型,我们希望为新关系中的所有现有实体自动创建实例和关系;
- 我们添加一个具有1:1子关系的父级,我们也希望在创建父实体时创建相关的1:1子实体;
- 在程序启动时,我们希望验证所有1:1子实体是否确实存在,如果不存在,则创建它们。目前情况就是如此。
我们将编写“修复现有数据”的代码,即上述场景3,这也将解决其他两个场景——递归要求意味着我们可以重用为给定实体类型创建1:1关系的代码。
/// <summary>
/// Create missing child entity instances and their relationships
/// to their parents for all parents in a 1:1 relationship with the child.
/// </summary>
protected void FixupOneToOneRelationships()
{
DataSet dataSet = ((DataSetProvider)dsp).DataSet;
DataTable dtRelType = dataSet.Tables["RelationshipType"];
// Get all 1:1 association types.
List<AssociationInfo> assocTypes = (from rt in dtRelType.AsEnumerable()
join entityAType in dataSet.Tables["EntityType"].AsEnumerable()
on rt.Field<int>("EntityATypeID") equals entityAType.Field<int>("ID")
where rt.Field<string>("Cardinality") == "1:1"
select new AssociationInfo()
{
RelationshipTypeID = rt.Field<int>("ID"),
EntityATypeID = rt.Field<int>("EntityATypeID"),
EntityBTypeID = rt.Field<int>("EntityBTypeID"),
EntityATypeName = entityAType.Field<string>("Name")
}).ToList();
CreateMissingRelationshipInstances(assocTypes);
}
protected void CreateMissingRelationshipInstances(int entityTypeID)
{
DataSet dataSet = ((DataSetProvider)dsp).DataSet;
DataTable dtRelType = dataSet.Tables["RelationshipType"];
// Get all 1:1 association types for the specific entity type.
List<AssociationInfo> assocTypes = (from rt in dtRelType.AsEnumerable()
join entityAType in dataSet.Tables["EntityType"].AsEnumerable()
on rt.Field<int>("EntityATypeID") equals entityAType.Field<int>("ID")
where (rt.Field<string>("Cardinality")) == "1:1" &&
(rt.Field<int>("EntityBTypeID")==entityTypeID)
select new AssociationInfo()
{
RelationshipTypeID = rt.Field<int>("ID"),
EntityATypeID = rt.Field<int>("EntityATypeID"),
EntityBTypeID = rt.Field<int>("EntityBTypeID"),
EntityATypeName = entityAType.Field<string>("Name")
}).ToList();
CreateMissingRelationshipInstances(assocTypes);
}
protected void CreateMissingRelationshipInstances(List<AssociationInfo> assocTypes)
{
DataSet dataSet = ((DataSetProvider)dsp).DataSet;
DataTable dtEntityInst = dataSet.Tables["EntityInstance"];
DataTable dtRelInst = dataSet.Tables["RelationshipInstance"];
// Verify relationship instance exists.
// First, get all the relationships that exist for a particular
// 1:1 association, based on the parent association type ID (entity B)
foreach (var assoc in assocTypes)
{
// Get all parent instances that should have 1:1 association type with children.
var childParentEntityInstances = from ri in dtRelInst.AsEnumerable()
join entityAInst in dtEntityInst.AsEnumerable()
on ri.Field<int>("EntityAID") equals entityAInst.Field<int>("ID")
join entityBInst in dtEntityInst.AsEnumerable()
on ri.Field<int>("EntityBID") equals entityBInst.Field<int>("ID")
where (entityBInst.Field<int>("EntityTypeID") == assoc.EntityBTypeID)
select new {A = entityAInst, B = entityBInst};
// This returns a list of all parents in an association with the "B" 1:1 association type.
// Next, get all the entity instances of the "B" type.
// Copy to a List<> so that we can modify the dtEntityInst table.
var allParentInstances = (from ei in dtEntityInst.AsEnumerable()
where ei.Field<int>("EntityTypeID") == assoc.EntityBTypeID
select ei).ToList();
// Each parent instance should be in a 1:1 relationship with the current association.
// We inspect all the relationship instances for this "B"
// type to see if it's missing for each parent instance.
foreach (var parentInst in allParentInstances)
{
// For all these parents, do they actually have a 1:1
// relationship instance with the child for the entity type in question ?
if (!childParentEntityInstances.Any(t =>
(t.A.Field<int>("EntityTypeID") == assoc.EntityATypeID) &&
(t.B.Field<int>("ID") == parentInst.Field<int>("ID"))))
{
// No. Create an entity instance of the "A" entity type
DataRow instance = dtEntityInst.NewRow();
instance["EntityTypeID"] = assoc.EntityATypeID;
instance["Comment"] = assoc.EntityATypeName;
dtEntityInst.Rows.Add(instance);
// Create the relationship.
DataRow relInst = dtRelInst.NewRow();
relInst["EntityAID"] = instance["ID"];
relInst["EntityBID"] = parentInst.Field<int>("ID");
relInst["RelationshipTypeID"] = assoc.RelationshipTypeID;
relInst["CreatedOn"] = DateTime.Now;
dtRelInst.Rows.Add(relInst);
// Recurse into the entity type whose child instance we just created.
CreateMissingRelationshipInstances(assoc.EntityATypeID);
}
}
}
}
持久化1:1关系中所有实体的数据
如果保存上述更改,状态值将不会持久化,因为它们实际上不属于Project实体。相反,我们需要确定1:1关系中的实际实体实例。这利用了我们在合并1:1实体类型时在AttributeInfo集合中保留的ParentEntityTypeID。有了这些信息,我们可以识别正确的实体实例ID,但这需要递归地遍历1:1关系实例以获取正确的子实体实例
case DataTableTransactionRecord.RecordType.ChangeField:
{
AttributeInfo attr = columnAttributeInfoMap[dttr.ColumnName];
// The ParentEntityTypeID will not be null
// if this is a 1:1 relationship to a child entity instance.
if (attr.ParentEntityTypeID != null)
{
// This is the top level parent entity instance.
// We need to recurse through the 1:1 relationships until we find
// the child entity that is itself a parent in the relationship
// specified by the attribute's EntityTypeID and ParentEntityTypeID.
entityID = dttr.Row.Field<int>("EntityID");
entityID = GetAssociatedParentEntity(entityID, attr.EntityTypeID,
attr.ParentEntityTypeID.Value).Item1;
}
else
{
entityID = dttr.Row.Field<int>("EntityID");
}
...
和
/// <summary>
/// Recurse until we find the relationship instance in which
/// A Type ID == entityTypeID and B Type ID == parentEntityTypeID, starting
/// from the current entity B instance. This is just for 1:1 relationships.
/// </summary>
protected Tuple<int, bool> GetAssociatedParentEntity(int entityID,
int entityTypeID, int parentEntityTypeID)
{
Tuple<int, bool> ret = new Tuple<int, bool>(-1, false);
DataTable dtRelInst = dataSet.Tables["RelationshipInstance"];
DataTable dtEntityInstance = dataSet.Tables["EntityInstance"];
DataTable dtRelationshipType = dataSet.Tables["RelationshipType"];
var assocTypes = from rel in dtRelInst.AsEnumerable()
join relType in dtRelationshipType.AsEnumerable()
on rel.Field<int>("RelationshipTypeID") equals relType.Field<int>("ID")
where (relType.Field<string>("Cardinality") == "1:1") &&
(rel.Field<int>("EntityBID")==entityID)
select new
{
EntityATypeID = relType.Field<int>("EntityATypeID"),
EntityBTypeID = relType.Field<int>("EntityBTypeID"),
EntityAID = rel.Field<int>("EntityAID"),
EntityBID = rel.Field<int>("EntityBID"),
};
if (!assocTypes.Any(t => (t.EntityATypeID == entityTypeID) &&
(t.EntityBTypeID == parentEntityTypeID)))
{
foreach (var assoc in assocTypes)
{
// Drill into a possible child.
Tuple<int, bool> ret2 = GetAssociatedParentEntity(
assoc.EntityAID, entityTypeID, parentEntityTypeID);
if (ret2.Item2)
{
return ret2;
}
}
}
else
{
entityID = assocTypes.Single(t => (t.EntityATypeID ==
entityTypeID) && (t.EntityBTypeID == parentEntityTypeID)).EntityAID;
ret = new Tuple<int, bool>(entityID, true);
}
return ret;
}
上面这段令人愉快的代码现在提取了1:1关系的正确实体实例,然后可以保存属性值了。
创建父实体时创建子1:1实体实例
我们还需要创建子实体实例。为此,我们可以重用修复例程中编写的一些代码,并在现有的“NewRow”案例中添加一行代码
case DataTableTransactionRecord.RecordType.NewRow:
{
DataRow newEntityRow = dtEntityInstance.NewRow();
newEntityRow["EntityTypeID"] = entityTypeID;
dtEntityInstance.Rows.Add(newEntityRow);
entityID = newEntityRow.Field<int>("ID");
dttr.Row["EntityID"] = entityID; // save to the physical table field.
// Create 1:1 instances as well, recursively.
CreateMissingRelationshipInstances(entityTypeID);
break;
}
删除1:1实体实例
当父实体被删除时,所有与该父实体有1:1关系的实体(递归地)都需要被删除
protected void DeleteAssociatedOneToOneInstances(int entityID)
{
DataTable dtRelInst = dataSet.Tables["RelationshipInstance"];
DataTable dtEntityInstance = dataSet.Tables["EntityInstance"];
DataTable dtRelationshipType = dataSet.Tables["RelationshipType"];
var entityAList = from rel in dtRelInst.AsEnumerable()
join relType in dtRelationshipType.AsEnumerable()
on rel.Field<int>("RelationshipTypeID") equals relType.Field<int>("ID")
join A in dtEntityInstance.AsEnumerable()
on rel.Field<int>("EntityAID") equals A.Field<int>("ID")
where (relType.Field<string>("Cardinality") == "1:1") &&
(rel.Field<int>("EntityBID") == entityID)
select A;
// 0 or 1 records should be returned.
foreach (var entityA in entityAList)
{
int childEntityID = entityA.Field<int>("ID");
dtEntityInstance.Rows.Remove(entityA);
DeleteRowAttributes(childEntityID);
DeleteAssociatedOneToOneInstances(childEntityID);
DeleteRelationshipInstances(childEntityID);
}
}
protected void DeleteRelationshipInstances(int entityID)
{
DataTable dtRel = dataSet.Tables["RelationshipInstance"];
var relInstances = from relInst in dtRel.AsEnumerable()
where (relInst.Field<int>("EntityAID") == entityID) ||
(relInst.Field<int>("EntityBID") == entityID)
select relInst;
foreach (var relInst in relInstances)
{
dtRel.Rows.Remove(relInst);
}
}
protected void DeleteRowAttributes(int entityID)
{
DataTable dtEntityInstance = dataSet.Tables["EntityInstance"];
foreach (DataRow row in dtEntityInstance.Select("ID = " + entityID))
{
row.Delete();
DeleteAssociatedOneToOneInstances(entityID);
}
}
加载1:1关系中实体属性的字段值
现在我们需要补充——将值加载到与父级具有1:1关系的子实体的物理表中。这涉及重构(我仍然认为这是一个愚蠢的词,为什么不直言不讳呢,它是返工、修复、更改,我的意思是,“refactor”甚至不是一个词,尽管“refactoring”在“计算机词典”中很奇怪地是,至少称之为“factoring”,因为这意味着“将方程、公式、密码等分解成其组成部分的行为或过程”,这至少是这里发生的事情,但我离题了)PopulatePhysicalTable方法,添加一行
...
foreach (DataRow entityInstance in entityInstances)
{
...
PopulateOneToOneEntityAttributes(row, entityID, entityTypeID);
...
}
该方法负责获取子实例、类型的属性以及设置行列表的字段(如果存在)
protected void PopulateOneToOneEntityAttributes(DataRow row, int entityID, int entityTypeID)
{
var oneToOneFields = attributes.Where(t => t.ParentEntityTypeID == entityTypeID);
DataTable dtAttributeType = dataSet.Tables["AttributeType"];
DataTable dtEntityAttributeInstance = dataSet.Tables["EntityAttributeInstance"];
DataTable dtEntityInst = dataSet.Tables["EntityInstance"];
DataTable dtRelInst = dataSet.Tables["RelationshipInstance"];
foreach (AttributeInfo ai in oneToOneFields)
{
// Get the child entity instance that is in a 1:1 relationship with the parent instance.
int childEntityID = (from rel in dtRelInst.AsEnumerable()
join entityA in dtEntityInst.AsEnumerable()
on rel.Field<int>("EntityAID") equals entityA.Field<int>("ID")
join entityB in dtEntityInst.AsEnumerable()
on rel.Field<int>("EntityBID") equals entityB.Field<int>("ID")
where entityB.Field<int>("EntityTypeID") == ai.ParentEntityTypeID &&
entityA.Field<int>("EntityTypeID") == ai.EntityTypeID &&
rel.Field<int>("EntityBID") == entityID
select rel.Field<int>("EntityAID")).Single();
DataRow[] attributeValues = dtEntityAttributeInstance.Select(
"EntityID=" + childEntityID + " and AttributeTypeID=" + ai.ID);
// No attribute value instance may exist yet.
if (attributeValues.Length == 1)
{
row[ai.ColumnName] = attributeValues[0]["Value"];
}
// Recurse.
PopulateOneToOneEntityAttributes(row, childEntityID, ai.EntityTypeID);
}
}
是的,所有那些“dt...”的初始化都可以删除。
其他功能
孤立实体和简单的项目-任务报告是当前实现中的另外两个功能。
孤立实体
ROP不强制实体实例必须与其他实体实例存在关系。此外,如果您删除一个实体实例,虽然任何关系实例都被删除,但它可能导致孤立记录,因此能够检查孤立记录很有用。孤立实体很容易确定:
protected void InternalLoadOrphanTable()
{
// The nullable collection of int's is used here in case a relationship
// has been created (by accident!) that does not define any entities.
// Get all the entity A Id's
List<int?> entityIDs = (from row in dataSet.Tables["RelationshipInstance"].AsEnumerable()
select row.Field<int?>("EntityAID")).Distinct().ToList();
// Add the entity B Id's
entityIDs.AddRange((from row in dataSet.Tables["RelationshipInstance"].AsEnumerable()
select row.Field<int?>("EntityBID")).Distinct().ToList());
// Yes, this means we potentially will have some none distinct ID's, but it doesn't really matter.
DataTable dtEntityInstance = dataSet.Tables["EntityInstance"];
DataRow[] entityInstances = (from row in dtEntityInstance.AsEnumerable()
where row.Field<int?>("EntityTypeID") == entityTypeID &&
!entityIDs.Contains(row.Field<int>("ID"))
select row).ToArray();
PopulatePhysicalTable(entityInstances);
}
上述代码获取所有参与关系的实体ID(实体A + 实体B),然后返回所有未在该列表中找到的实体实例。结果行集合是所有未与其他实体实例存在关系的实体实例——换句话说,就是孤立实体。一个更简单的UI允许用户关联这些实体

上面的截图显示了我想与项目关联的孤立任务。
报告
好的,我真的很想为我正在做的其他工作准备一份“项目任务”报告,所以我用OpenXML编写了一份报告,生成了一个Word文档。(弄清楚如何用样式创建一个简单文档费了很大劲,幸运的是网上有很多例子。)查询非常有趣,并说明了模型数据和应用程序数据之间的区别。
我们首先创建具体的项目表
EntityProvider epProject = new EntityProvider(dataSet);
epProject.InitializeWithApplicationEntity("Project");
epProject.LoadTable();
还有具体的任务表
EntityProvider epTask = new EntityProvider(dataSet);
epTask.InitializeWithApplicationEntity("Task");
epTask.LoadTable();
这些是“应用程序”表(在数据集中由EntityType、EntityInstance、EntityAttributeInstance和AttributeType物理表抽象表示),而关系表是数据集本身中的具体表
DataTable dtRel = dataSet.Tables["RelationshipInstance"];
然后我们遍历每个项目
foreach (var project in
from proj in epProject.DataTable.AsEnumerable()
orderby proj.Field<string>(epProject.GetColumnNameMapping("Name"))
select new
{
ID = proj.Field<int>("ID"),
EntityID = proj.Field<int>("EntityID"),
Name = proj.Field<string>(epProject.GetColumnNameMapping("Name"))})
然后查询与项目相关的任务关系
var tasks =
from r in dtRel.AsEnumerable() where r.Field<int>("EntityBID") == project.EntityID
join t in epTask.DataTable.AsEnumerable() on r.Field<int>("EntityAID") equals t.Field<int>("EntityID")
orderby t.Field<string>(epTask.GetColumnNameMapping("Name"))
select new
{
ID = t.Field<int>("ID"),
Name = t.Field<string>(epTask.GetColumnNameMapping("Name")),
Descr = t.Field<string>(epTask.GetColumnNameMapping("Short Description")) };
上述代码选择项目是“主”实体(实体B)的关系,并连接到任务表,其中“详细”实体(实体A)是一个任务,因此我们得到属于特定项目的任务。此查询连接了应用程序表(在运行时从模型数据生成)和模型表。有其他方法可以实现此目的(例如,可以编写一个将任务按项目分组的单一查询),但我想保持查询的清晰性,以便更容易调试它们。
最后,我们迭代任务
foreach (var task in tasks)
{
para = body.AppendChild(new Paragraph());
run = para.AppendChild(new Run());
// Name if Descr is null.
text = new Text(task.Descr ?? task.Name);
run.AppendChild(text);
}
结果是一个如下所示的docx文件

这是一个非常有用的原型,展示了报表生成器将如何查询模型和应用程序数据集以导航实体层次结构和属性。
只是为了好玩
当前模型实体关系图(ERD)——已水平压缩

GAPMA ERD,严重压缩,点击此处查看完整尺寸版本。
{kind=link}

鉴于只有18个实体,这通常不是您在典型的ERD中会看到的情况。我认为它说明了使用ROP的关系的丰富性。
结论
ROP概念持续让我惊讶的是,添加实体和属性如何能够立即以高效的方式增强目标应用程序。它还有助于思考实体之间应该如何关联,这是ROP(关系)的关键点之一。我还注意到,实现特定功能所需的代码通常以小包形式出现(但我的组织结构缺乏!)
后续概念
可能通过包装代码统一分层布局问题,以便可以使用单个UI,但用于实例化包装器。
自动审计追踪——跟踪属性值的变化。
筛选预设
筛选预设(例如筛选到特定的项目实例)在哪里以及如何应用?当对被筛选实体(例如项目)的引用可能与当前实体实例集合相距数跳时,如何处理?例如,如果存在以下关联:
项目 -> 用户故事 -> 任务 -> 缺陷
我们如何只筛选与项目实例关联的缺陷?
查询
特别是通过关联实体确定的字段(如项目)进行筛选的查询。
工作流
例如,我们可以将工作流定义为任务 -> 测试 -> 审查 -> 批准中每个步骤的完成。
规则
如上所述,有些规则本质上定义了工作流。例如:
现在我们遇到一个重要的问题:当建立关联(任务分配给某人)时,这应该自动改变相关Progress实体的状态。
当任务完成时,与任务关联的“审查”的“进度”状态可以从“未就绪”设置为“未分配”。“批准”实体也是如此。相反,当与用户故事关联的“批准”实体状态设置为“已批准”时,与用户故事关联的“任务”实体可以设置为“未分配”状态。更有趣的是,您可能有一个项目负责人负责所有审查,因此他可以被自动分配,并且“进度”状态更改为“已分配但工作未开始”。
更多示例:当冲刺中的所有任务都已分配时,可能会有一个规则更改与冲刺关联的进度状态。迭代也是如此。当所有任务都完成时,状态可以再次更改为“已完成”。
级联删除
应在关系类型中创建一个标志,以确定删除实体实例是否也应:
- 删除任何子实例
- 或仅删除仅由该关系引用的子实例
- 或额外例外
例如
- 如果一个项目被删除,所有任务、缺陷、迭代等是否也应该被删除?
- 如果一个用户故事被删除,即使任务引用了一个项目,该用户故事的所有任务是否也应该被删除?
- 如果一个缺陷被删除,即使需求有一个关联文档,所有需求是否也应该被删除?
- 如果一个用户故事被删除,即使任务属于一个组,所有任务是否也应该被删除?
- 如果一个组被孤立,我们该怎么办?
这些场景都应该通过明确、声明性的规则来处理。这里的突出点是,我们必须有意识地思考这些级联规则,而不是盲目地做出假设,通过声明性地公开规则,我们可以在不影响代码的情况下修改应用程序的行为。
删除关系
删除关系、孤立实体等也有规则。
更改关系
同样,更改关系以及更改可能产生的孤立对象也有规则。
Excel 导出/导入
对于不同的模型和应用程序数据集,将数据导出/导入到Excel会很有用。
清理选择列表问题
这个令人尴尬的问题就到此为止吧。
其他小细节
到目前为止,令人恼火的一件事是,在编辑应用程序数据时,我必须记住点击“保存”按钮才能将“虚拟”表数据持久化回ROP实体-属性表。
另一个小细节是,当我编辑模式或模型时,我必须重新加载数据集,以便模式和模型实体及属性反映在.NET DataSet中。
此外,孤立实体编辑器需要是实体编辑器的派生类——现在它缺少我已添加到实体编辑器的一些功能,并且其行为中存在大量的代码重复。
目前有一个限制,即一个实体不能有两个或更多相同类型的属性,因为这会导致相同的名称映射到物理表中的多个虚拟列。您可以在nameColumnMap字典中看到这种情况,其中包含与Task等实体1:1关系中的“状态”属性。这在1:1关系场景中不是问题,因为在这种情况下不使用nameColumnMap,但这是一个更大的问题,需要通过别名字段名和列标题来解决。
在关系数据库管理系统中折衷经典的建模方法
即使您决定为最终应用程序创建自定义表和UI,ROP IDE也是一个出色的概念验证工作模式工具,并为用户提供了探索用例的初始工具——用敏捷术语来说就是用户故事。这引出了我想提及的一点:大多数开发人员(如果不是全部)都会(甚至应该)对使用单个表作为所有实例实体及其属性的容器的想法感到犹豫。同样,就性能而言,使用单个表作为所有关联的容器也同样值得怀疑。第一个问题可以通过修改ROP元模型来解决,使其可以与单个表一起工作,这相当容易实现,我希望将来进一步探索。具有主键、唯一键和其他索引列的独立表将提高性能。然而,为了利用ROP的灵活性,这些表将没有外键,因此需要一个单独的池化关联表或离散关联表。同样,这是我希望将来探索的问题,以期解决企业级应用程序数据的性能问题。
暂告一段落,各位
一篇冗长得离谱的文章,但它解决了我在ROP IDE本次迭代中想要实现的关键功能。