
AI 队列长度检测:使用 YOLO 进行图像对象检测
5.00/5 (1投票)
在本文中,我们将比较从头开始训练我们的模型,以及更高级的、预训练的方法,如 YOLO。
在本系列的先前文章中,我们从头开始实现了目标检测。我们观察到从头开始训练一个模型需要大量的计算资源和时间。这些算法训练和测试速度都很慢,并且几乎不可能在实际中有效地实现它们。 重点转向以速度为导向的解决方案,You Only Look Once (YOLO) 是当今最流行的目标检测方法。
YOLO 简介
YOLO,顾名思义,只需要一次前向传播即可检测给定图像中的对象。 同样的特性使 YOLO 能够在保持合理准确性的同时,以最小的延迟处理实时视频。
我们之前在本系列中讨论的所有目标检测算法都使用区域来定位图像中的目标。 它们获取图像中包含感兴趣对象的可能性很高的部分,而不查看整个图像。 另一方面,YOLO 获取一个图像并将其分割成网格。 然后我们在每个网格单元上运行一个定位算法,这会产生例如 m 个边界框。 网络将为每个边界框输出一个类别概率和边界框的偏移值。 最后,该算法选择类别概率高于阈值的边界框,并在图像中定位对象。 让我们看看 YOLO3 的一个简单实现,以了解检测是如何发生的。
创建和加载模型
让我们从导入必要的库开始。 我们将使用 Keras 来实现它。
import cv2
import numpy as np
由于我们正在使用预先训练的模型,因此我们需要下载特定的权重和配置文件。 从 这里 获取权重文件,从 这里 获取配置文件。 指定的模型在 MS COCO 数据集上进行训练,该数据集可以识别 80 个类别的对象。 您可以从 这里 下载或复制 coco.names。
下载所需文件后,我们可以继续创建和加载我们的模型。 OpenCV 提供了 readNet 函数,该函数用于将深度学习网络加载到系统中。 深度学习网络必须以受支持的格式之一表示,例如 xml 和 prototxt。 加载模型后,我们将向我们的模型提供要从 coco.names 文件中识别的类。 然后,我们使用 getLayerNames 函数检索输出层,并使用 getUnConnectedOutLayers 将它们存储为输出层列表。
# Use readNet to load Yolo
net=cv2.dnn.readNet("./yolov3.weights", "./yolov3.cfg")
# Classes
Classes = []
with open("coco.names","r") as f:
classes = [line.strip() for line in f.readlines()]
# Define Output Layers
layer_names =net.getLayerNames()
output_layers = [layer_names[i[0]-1] for i in net.getUnconnectedOutLayers()]
预处理输入
现在我们可以通过我们的模型传递图像,但是该模型希望图像具有特定的形状。 为了使我们的图像形状与模型输入的形状兼容,我们将使用 blobFromImage。 该函数将重新调整图像的形状,并按正确的顺序重新排序我们图像的颜色通道。 然后我们把图像给模型进行前向传递。 前向传递输出一个检测列表。
#reshape, normalize and re-order colors of image using blob
blob = cv2.dnn.blobFromImage(img,1/255,(416,416),(0,0,0),True,crop=False)
# blob as input
net.setInput(blob)
#Object Detection
results = net.forward(outputlayers)
获取边界框
我们可以使用此输出结果来获取每个检测到的对象的边界框的坐标。 如前所述,我们然后使用阈值来获取准确的边界框。
# Evaluate class ids, confidence score and bounding boxes for detected objects
class_ids=[]
confidences=[]
boxes=[]
confidence_threshold = 0.5
for result in results:
for detection in result:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence> confidence_threshold:
# Object Detected
center_x=int(detection[0]*width)
center_y=int(detection[1]*height)
w=int(detection[2]*width)
h=int(detection[3]*height)
# Boundry box Co-ordinates
x=int(center_x-w/2)
y=int(center_y-h/2)
boxes.append([x,y,w,h])
confidences.append(float(confidence))
class_ids.append(class_id)
现在我们有了边界框坐标,我们可以继续在检测到的对象上绘制框并标记它。 但是我们事先不知道任何给定对象的出现次数。 为了克服这个问题,我们将使用 NMSBoxes 函数,该函数采用非最大抑制。 之后,我们最终显示图像。
# Non-max Suppression
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.4, 0.6)
# Draw final bounding boxes
font = cv2.FONT_HERSHEY_PLAIN
count = 0
for i in range(len(boxes)):
if i in indexes:
x,y,w,h = boxes[i]
label = str(classes[class_ids[i]])
color = COLORS[i]
cv2.rectangle(img, (x,y), (x+w, y+h), color, 2)
cv2.putText(img, label, (x, y-5), font, 1, color, 1)
最后一步是将所有内容放在一起,并显示带有检测到的对象的最终图像。
cv2.imshow("Detected_Images",img)

这很简单,对吧? 但等等——我们可以修改相同的代码来计算图像中人物的数量吗? 让我们看看。
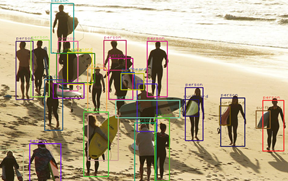
MS COCO 数据集可以识别 80 个不同的类别,包括人物。 我们可以通过计算类别“人物”的出现次数来轻松计算图像中存在的人数。
if int(class_ids[i] == 0):
count +=1
上述小修改返回图像中存在的人数。 前一张图片返回的人数为 2,下一张图片的计数为 18
接下来是什么?
在本文中,我们学习了 YOLO 进行目标检测的基本实现。 我们看到使用预先训练的模型来节省时间和计算资源是相当容易的。 在下一篇文章中,我们将看看我们是否可以在视频源上实现 YOLO 来进行队列长度检测。 作为结尾,我们还将讨论我们希望使用自定义训练模型而不是预先训练模型的场景。