
预处理时间序列数据以进行 AI 预测和异常检测
5.00/5 (4投票s)
在本文中,我们将学习如何准备时间序列数据以输入机器学习(ML)和深度学习(DL)模型。
引言
本系列文章将指导您完成使用AI开发功能齐全的时间序列预测器和异常检测器应用程序所需的步骤。我们的预测器/检测器将处理加密货币数据,特别是比特币。但是,在跟随本系列之后,您将能够将所学的概念和方法应用于任何性质相似的数据类型。
为了充分利用本系列,您应该具备一些Python、机器学习和Keras技能。整个项目可在我的"GitHub存储库中找到。您也可以在此处和此处查看完全交互式的Notebook。
在本系列的上一篇文章中,我们讨论了时间序列数据的性质和重要性。在这篇文章中,您将学习如何将数据转换为可用于训练神经网络预测模型和异常检测器的数据形式。
我们将大部分时间与比特币价格打交道。我在Kaggle上找到了一个完整的数据集。为了澄清一些概念和想法,我们将使用一个我从NOAA网站获取的天气数据集。请继续下载这些数据集以进行跟进。在此项目中,我将使用Kaggle Notebooks – 但您可以使用任何其他云Notebook,甚至您的本地计算机。
检查、重新格式化和清理比特币数据集
在开始检查之前,让我们导入本项目将使用的所有库。如果您的Notebook无法导入其中任何一个,请记住您可以使用终端中的pip命令来安装它们。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
import plotly.graph_objects as go
from sklearn.preprocessing import MinMaxScaler
import gc
import joblib
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.models import load_model
from sklearn.ensemble import IsolationForest
from sklearn.cluster import KMeans
import json
import urllib
from datetime import datetime, timedelta,timezone
import requests
现在,让我们加载包含从2011年12月到2020年12月(以分钟为间隔 - 大约400万个样本)的比特币历史的.csv文件,并显示前几行。文件路径是/kaggle/input/bitcoin-historical-data/bitstampUSD_1-min_data_2012-01-01_to_2020-1。
btc = pd.read_csv('/kaggle/input/bitcoin-historical-data/bitstampUSD_1-min_data_2012-01-01_to_2020-12-31.csv')
btc.head()
您现在将能够初步了解

请注意,“Timestamp”列应以日期格式表示,但目前以Unix格式表示。为了将其切换到正确的格式,让我们这样做
btc['Timestamp'] = pd.to_datetime(btc.Timestamp, unit='s')
btc.head()
这将把列格式更改为正确的格式

您可能会看到大多数列中有很多NaN值(空字段)。让我们选择“Weighted_Price”以关注单变量方法,保持简单。我们将重新采样观测值,并获得每小时而不是每分钟等距的点,因为您不会期望在短时间内看到大的变化,因此您将拥有大量冗余数据。
btc = btc[['Timestamp','Weighted_Price']]
btc = btc.resample('H', on='Timestamp')[['Weighted_Price']].mean()
现在,让我们看一下整个图景,以直观地理解需要删除数据集的哪个部分以检测数据不连续性并去除无意义的数据
pano = btc.copy() #We're going to use this later
fig = go.Figure()
fig.add_trace(go.Scatter(x=pano.index, y=pano['Weighted_Price'],name='Full history BTC price'))
fig.update_layout(showlegend=True,title="BTC price history",xaxis_title="Time",yaxis_title="Prices",font=dict(family="Courier New, monospace"))
fig.show()

在上图中,您会注意到从2012年到2013年中期存在一些不连续性。此外,直到2017年中期的趋势数据是无用的,因为比特币价格不太可能回落到接近零的值。您不希望将无关数据输入到未来的模型中,因此让我们截断数据集,只包含有意义的值,并用其下一个非空邻居替换空值。
btc = btc.iloc[51000:]
btc.fillna(method ='bfill', inplace = True)
print('NaN values: ',btc.isna().sum())
现在您拥有一个不包含任何空值的数据集。数据点从2017-10-25 07:00:00开始,您的新集合有27906个值。如果再次绘制数据集,您应该会得到类似这样的图

拆分比特币数据集
正如您可能知道的,将一部分数据集用于训练模型,另一部分用于测试模型是一种常见的做法。在这种特殊情况下,我们需要选择连续的部分,这就是为什么我将取前20%的值作为测试集,最后80%作为训练集。为此,请执行以下操作
data_for_us = btc.copy() #To be used later on Unsupervised Learning
training_start = int(len(btc) * 0.2)
train = btc.iloc[training_start:]
test = btc.iloc[:training_start]
现在,您的训练集和测试集的形状分别为(22325, 1)和(5581, 1)。
缩放比特币数据集
在实现任何机器学习/深度学习模型(ML/DL)之前,此步骤至关重要。没有它,模型的收敛速度将很慢;甚至可能模型在训练后永远无法达到好的结果。通常,这是因为拟合异构值所需的参数调整非常消耗资源。我们可以将此步骤定义为将数据范围调整到使任何ML/DL模型更容易收敛的小值。
让我们先通过执行以下命令来拟合缩放器
scaler = MinMaxScaler().fit(train[['Weighted_Price']])
请注意,我们使用的是Scikit-Learn中的MinMaxScaler方法。我将从官方文档网站摘录其描述:“此估计器独立地缩放和平移每个特征,使其在训练集上的指定范围内,例如零到一之间。”人们在处理缩放器时常常犯的一个错误是将其拟合到所有可用数据上。这不是一个适当的方法;您必须仅在训练集上拟合缩放器。为了保存缩放器以供将来使用并缩放训练集和测试集,请执行这些命令
joblib.dump(scaler, 'scaler.gz')
scaler = joblib.load('scaler.gz')
def scale_samples(data,column_name,scaler):
data[column_name] = scaler.transform(data[[column_name]])
return data
train = scale_samples(train.copy(),train.columns[0],scaler)
test = scale_samples(test,test.columns[0],scaler)
现在,如果您检查表格,您会注意到所有值都在0到1之间。这就是我们想要的,对吧?
生成序列并创建数据集
正如我在上一篇文章中提到的,我们希望检测当前和未来比特币价格的异常。让我们澄清一下。首先,我们需要使用过去和当前的数据来预测未来的价格值,然后确定整个数据图像中的异常。让我通过图形进一步澄清这一点。
这是您通常在一个序列数据集中会遇到的情况

假设t = n是当前日期和时间。我们想要预测价格值,例如,在t = n+1时,基于t = 0到t = n的数据,并在整个窗口(t = 0 到 t = n+1)中检测异常。就像这样

为了实现这一点,您需要将整个数据集分割成小块序列,然后可以将其传递给模型。在这种情况下,我们想将过去24小时的比特币价格传递给模型,并预测下一个小时的价格。为此,我们定义一个lookback作为过去窗口的步数,lookforward作为未来窗口的步数
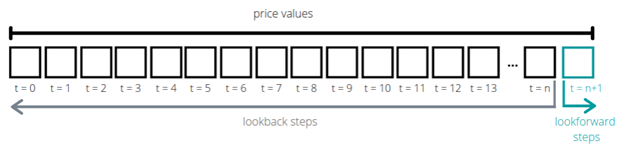
在代码中,该函数将是
def shift_samples(data,column_name,lookback=24):
data_x = []
data_y = []
for i in range(len(data) - int(lookback)):
x_floats = np.array(data.iloc[i:i+lookback])
y_floats = np.array(data.iloc[i+lookback])
data_x.append(x_floats)
data_y.append(y_floats)
return np.array(data_x), np.array(data_y)
这将返回两个NumPy数组,第一个用于lookback块,第二个用于lookforward块。现在调用此函数,并将测试集和训练集传递以创建我们将要使用的数据集
X_train, y_train = shift_samples(train[['Weighted_Price']],train.columns[0])
X_test, y_test = shift_samples(test[['Weighted_Price']], test.columns[0])
最后,要了解集合的最终形状,请执行这些命令
print("Final datasets' shapes:")
print('X_train: '+str(X_train.shape)+', y_train: '+str(y_train.shape))
print('X_test: '+str(X_test.shape)+', y_train: '+str(y_test.shape))
这将返回
Final datasets' shapes:
X_train: (22301, 24, 1), y_train: (22301, 1)
X_test: (5557, 24, 1), y_train: (5557, 1)
如果您想增加lookforward步数,您将需要稍微修改函数
def shift_samples(data,column_name,lookback=30,lookforward=2):
data_x = []
data_y = []
for i in range(len(data) - int(lookback)-int(lookforward)):
x_floats = np.array(data.iloc[i:i+lookback])
y_floats = np.array(data.iloc[i+lookback:i+lookback+lookforward])
data_x.append(x_floats)
data_y.append(y_floats)
return np.array(data_x), np.array(data_y)
请记住,如果您修改shift_sample函数并增加lookforward步数,您还需要修改传入的模型。我创建了一个Notebook,我在其中开发了这样的方法。要获得完整的Notebook交互性,请查看Kaggle上的Notebook。
下一步
在下一篇文章中,我们将深入探讨时间序列数据的异常检测,并了解如何构建可以执行此任务的模型。敬请关注!