
CityPulse:Facebook 事件可以变得更多
4.93/5 (16投票s)
一个基于Azure的软件解决方案,让用户能够大规模发现身边的活动。特色包括ASP.net MVC4、Entity Framework以及利用Azure虚拟机的大型导入后端。

请注意:我们最近更名为“CityPulse”(并为网站增加了新功能!)。本文中的文字和链接已更新,但带有“whatsonglobal”标志的原始图片仍然保留。阅读愉快!
想法
Facebook是世界上最大的活动数据库。它包罗万象,从一个人只有几个朋友的生日聚会,到成千上万人参加的盛大节日和全球性集会。
那么,你如何使用Facebook活动呢?我们大多数人会发送私人邀请参加生日派对,或者告知我们的好友列表我们正在参加本周的体育赛事。大多数人没有意识到的是,Facebook活动可以做的远不止于此。每天、每晚、每个周末和每个月,世界各地的每个城市都有成千上万的Facebook活动迫切地希望推广一部新电影、发起下一场新奇的潮流,或者在你家附近的街角宣传一项新的每周酒吧问答。
但是有一个问题——活动是孤立的。Facebook自身平台上的不足之处意味着很难轻松登录并找出这个即将来临的周末在你所在的地区有哪些精彩的活动正在进行。这就是CityPulse的用武之地。
通过单一视图,CityPulse Web应用程序将在交互式地图上向你展示正在进行的顶级活动、活动地点、活动日期以及有多少人参加。
想知道周五晚上做什么?CityPulse就是你的不二之选。
如何做到?
这得益于Facebook对人们活动的管理。只要Facebook活动的所有者将其标记为公开,那么根据服务条款,这些活动就可以被第三方应用程序导出和使用。只要活动信息保持最新,并且不售卖任何个人信息——那么像CityPulse这样的应用程序就可以被允许使用和显示数据。
那些搜索它的人可以找到令人惊讶数量的公开活动。营销人员、活动推广者和场地所有者非常乐意使用Facebook平台来接触尽可能大的目标受众。
这不仅仅是生日派对和家庭聚会!
目录
本文
现在,在我们戴上喜欢的开发者帽子并开始写代码之前,让我们先明确一下期望。
本文的目标读者是对技术充满热情,并且已经相当精通基于Microsoft的编程语言和技术的人。我们不会分析每一行代码,因为
- 这将耗费大量阅读时间。代码量很大,所以为了保持文章的简洁和趣味性,对大家都有好处。
- 本文的目的不是这个。我们将带你一起解决一些相当复杂的技术挑战,运用最新的技术和软件平台。这意味着我们将在很大程度上保持在架构层面,并在解决问题核心时深入技术细节。
本文将向你展示
- 开发具有复杂Azure后端网站所需的技术。
- 如何有效且优雅地以编程方式控制云部署。
- 如何设置Azure VM/云服务以从Facebook导入大量数据、进行处理并将其作为网站内容提供。
- 如何设置基于作业的调度组件,以管理云中的维护任务。
- 基于队列的云处理中的设计模式。
- 如何使用Facebook的FQL API提取活动信息。
- 如何使用人工智能解决现实世界的问题。
- 如何使用Entity Framework Code-First在云中快速开发数据库。
- 如何设置ASP.net MVC4和Web API以提供和渲染内容。
- 响应式设计如何使网站对尽可能多的设备友好。
希望您喜欢!
那么我们需要什么?
首先,我们需要访问Facebook活动。这将通过抓取Facebook的活动存档来实现。
其次,我们需要一个导入机制。所有这些活动都不会自己下载。需要定期导入、分类、过滤和更新活动。这并非易事——我们需要能够扩展以满足任何繁重需求的东西,以及一个可靠性高、几乎无需维护、并且在我们需要的时可以启动并承担重负荷的基础设施环境。这就是Azure发挥作用的地方,我们将在本文后面更深入地探讨。
第三,我们需要一些存储。那些导入的活动需要一个家,并且我们需要一个地方来管理和监控导入过程。此外,活动需要进行分类,并且登录我们应用程序的用户需要登录以保证安全。为此,我们将使用SQL Azure。这基本上就是标准的SQL,但它托管在云端。
最后,我们需要一个网站。这是所有内容汇集的地方。该网站将为全球受众提供那些精彩的活动。我们需要规模、安全和性能。Azure网站将很好地满足这一需求。
架构
在最高层面上,架构如下所示

让我们来看看图中的一些实体
 Windows Azure
Windows Azure
托管环境。我们将详细介绍这一点,但目前只需说Azure托管了CityPulse运行所需的所有基础设施。
 Facebook
Facebook
活动提供商。由于CityPulse将抓取和存储活动,因此Facebook和Azure之间存在连接。
 CityPulse管理员
CityPulse管理员
我们需要一个地方来管理导入过程。我们要运行哪些导入?何时安排?是否发生过错误?吞吐量如何?连接到维护数据库的桌面应用程序将为我们提供答案,并允许我们启动在工作节点上运行的导入会话。
 网站用户
网站用户
忠实的用户。他们只想加载网站并找到生活中精彩的事情。他们对活动是如何到来的毫不知情,他们只想去参加!
技术
Microsoft Azure
- Azure Websites:在云中托管网站。
- Azure Cloud Services:支持驱动导入过程的基础设施(PaaS)。
- Azure Storage:Blob存储,包含用于导入过程的虚拟机数据。消息队列消息存储在此处。
- Azure SQL:托管用于导入和活动信息的SQL数据库。
Microsoft ASP.net MVC 4:MVC的模型视图控制器方法。
ASP.net Web API:提供Json内容的RESTfulWebService实现。对于互操作性很重要。
Entity Framework:数据库抽象,可在数据访问层中实现快速开发。
- Code first - 从C#代码创建数据库模型。
- Database first - 从数据库模型创建C#代码。
Web库
- Javascript - 在网站上启用AJAX,对于流畅的界面至关重要。
- Typescript - 强类型库,位于javascript之上。对C#开发人员很棒。
- JQuery - Javascript的首选库。
- Google maps - 用于在网站上启用Google地图的API。
- Richmarker - 允许富HTML内容用于标记。
- Google autocomplete - 用于查找用户的地址。
- Less - 动态样式表。
- Knockout - Javascript中的MVVM实现。非常适合数据绑定。
- Modernizr - 兼容所有浏览器和屏幕分辨率。
- Moment - Javascript中出色的日期时间处理。
Azure Fluent Management - 一个用于管理Azure平台的“流畅”API。
Quartz.net - .net中的企业作业调度程序。
Prowl - 自动电话通知。
Json.Net - .Net中与Json之间快速的序列化。
Telerik Radcontrols - WPF的全面UI套件。
为什么选择 Azure?
我认为每个开发人员都会对这个问题给出不同的答案。对我而言,选择Azure可以归结为以下4个类别。
省心的基础设施。
对于这个解决方案,我们需要硬件。我们需要服务器来托管网站、数据库并运行事件导入服务。外部面向硬件保持安全非常重要,因此我们需要及时进行安全补丁,以及应用常规的Windows更新以保持安全。为了运行网站,我们需要配置和维护IIS,并且运行导入过程的平台需要持续关注才能保持正常运行。
在Azure上,我们不必担心这些事情。基础设施本身由微软维护,因此我们可以将宝贵的开发时间用于创建出色的软件。从安全方面来说,我们可以专注于保护将要向我们的网站提供事件的ASP.net Web API,而不是陷入保护最新操作系统漏洞的泥潭。在开发方面,我们可以投入时间来完善导入服务,并创建一个强大的服务来驱动我们的解决方案。
规模,规模,规模!
Azure在扩展方面做得非常出色。扩展使我们能够应对不断增长的用户群带来的繁重负载,并允许我们处理诸如在夜间导入大型批处理作业等繁重任务,以确保第二天尽可能多的活动得以展示。
在大多数情况下,可以通过Azure管理API或PowerShell命令来实现扩展。我将在本文后面更详细地介绍云环境中的典型扩展模式。
可靠性
微软的服务级别协议(SLA,可用性义务)规定了99.5%到99.9%的正常运行时间,具体取决于您使用的服务。这是一个相当不错的承诺,肯定比我们自己维护基础设施要好得多。尽管如此,Azure也曾出现过宕机——但幸运的是,诸如“地理复制”之类的选项允许我们将基础设施镜像到不同位置,并在遇到困难时进行故障转移。
与微软工具的重度集成
到目前为止,Azure提供的功能可以通过其他基于云的托管服务(如Amazon EC2)在一定程度上相匹配。集成是Azure发挥其优势的地方。如果您沉迷于Visual Studio——那么Azure的云编程将让您感到宾至如归。

将工作进程发布到云基础设施,或您网站的最新版本通常只需单击一下即可完成,而Code-First Entity Framework则在创建和维护我们的Azure SQL数据库时为我们提供了最大的效率。
使用Azure虚拟机进行导入流程
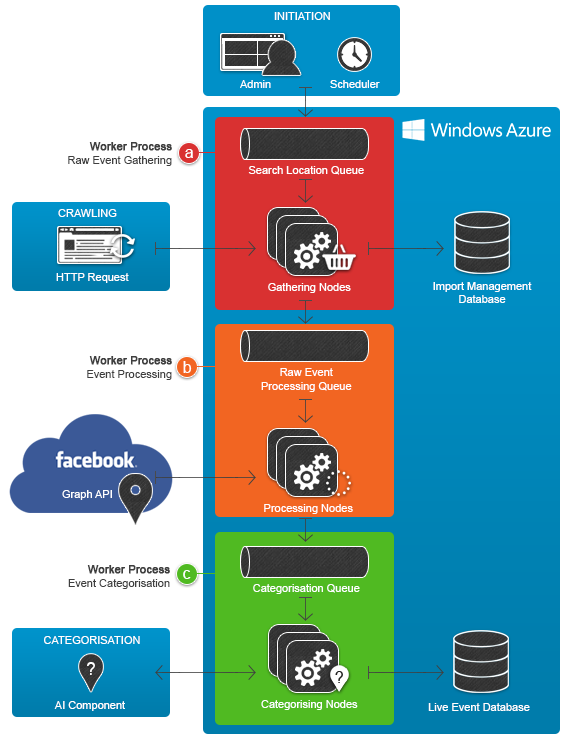 导入过程包括三个作业,以从Facebook挖掘活动、处理信息并将其存储在我们的实时活动数据库中,以便为我们的网站用户提供服务。这些作业使用基于队列的设计模式运行,以便它们可以扩展,并且由用户交互或Quartz.net调度的作业启动。
导入过程包括三个作业,以从Facebook挖掘活动、处理信息并将其存储在我们的实时活动数据库中,以便为我们的网站用户提供服务。这些作业使用基于队列的设计模式运行,以便它们可以扩展,并且由用户交互或Quartz.net调度的作业启动。
每个作业都称为“工作进程”。这是一个独立运行的代码模块,可以将其推送到云端以在我们的导入过程的域下运行。在Azure中运行时,工作进程代码以“Cloud Service”的形式运行,本质上是一个我们不直接控制的虚拟机。我们可以使用Visual Studio的Azure SDK插件来开发工作进程,并使用一次性发布方法将代码推送到Azure。在云中,此代码将被配置并运行,直到我们通过管理门户告诉它停止、它失败或我们发送命令将其关闭。
现在,在我们深入研究代码本身之前,我们的导入过程中有 3 个关键概念需要解释
- 使用Quartz.net调度作业:由于导入需求的大规模性质,初始化作业和任务需要自动化。Quartz.net提供了一个非常强大的作业调度引擎,可以很好地完成这项工作。
- 自动化云中的VM部署:管理门户很棒,但不足以实现完全自动化的解决方案。Elastacloud的开源“Fluent Management”库将帮助我们完成这项工作。
- 基于队列的设计模式:利用云中的规模来处理不同大小的工作负载至关重要。队列是关键。
使用Quartz.net调度作业
在全球范围内提取、处理和存储Facebook活动可能需要大量的管理工作,因此我们开发了一个小型WPF应用程序,用于处理初始化导入过程所需的一些自动化。该应用程序使用Quartz.net,一个全面的作业调度库,让我们能够规划导入过程的哪些部分何时运行。这里的目标是让它像钟表一样运行,利用Prowl.net、prowldotnet和自动电子邮件发送一些关于导入成功率的指标,以及在哪里需要关注(如果有的话)。

/// <summary>
/// Schedule a job to run based on a cron string
/// </summary>
/// <param name="job" /> The job abstraction to be fired
/// <param name="cronString" /> An expression representing when and how often to fire job
public ScheduledJobViewModel ScheduleJob(ImporterJobBase job, string cronString)
{
//use quartz.net to create a job and assign a UI
IJobDetail jobDetail = JobBuilder.Create(job.GetType())
.WithIdentity("Job - " + Guid.NewGuid().ToString(), job.Name)
.Build();
//create a trigger for the event to fire, using a cron string
ICronTrigger trigger = (ICronTrigger)TriggerBuilder.Create()
.WithIdentity("Trigger - " + Guid.NewGuid().ToString(), job.Name)
.WithCronSchedule(cronString)
.Build();
//schedule the job to run
_scheduler.ScheduleJob(jobDetail, trigger);
//return a UI representation of the job so it can be shown on the form
return new ScheduledJobViewModel()
{
CronExpression = cronString,
JobType = job.GetType().ToString(),
Name = job.Name
};
}
上面的代码描述了如何使用Quartz.net调度作业。Cron表达式提供了一种简洁而强大的方式来描述作业何时以及多久运行一次。
- 实时事件数据库清理的表达式为'0 00 06 * * ?'
- 每天早上6点删除冗余事件。
- 初始化数据收集(将队列添加到工作进程A)的表达式为'0 0 0 ? MON,THU,SAT'
- 每个星期一、星期四和星期六午夜,作业将为Azure中的新数据收集会话初始化队列。
- 完整导入过程(工作进程A-C)的表达式为'0 10 0 ? MON,THU,SAT'
- 每个星期一、星期四和星期六午夜后10分钟,作业将执行新的数据收集会话。
- 实时事件更新程序的表达式为'0 10 06 * * ?'
- 现有事件将在每天早上6:10刷新新数据。
作业本身范围广泛,从对实时数据库运行存储过程到打包工作进程并将其部署到Azure。只要它们实现了IJob接口,就可以被Quartz调度。
我们开发了一个抽象类(ImporterJobBase)来封装作业可以提供的一些通用功能,例如电子邮件/电话通知、错误和消息日志记录,以及允许传递给UI的配置。

Elastaclouds Azure Fluent Management
Azure Fluent Management库(fluentmanagement.elastacloud.com)是管理Azure云的一个特别有用的组件,尤其是在配置和部署存储以及云服务方面。
通常,对Azure SQL数据库部署、虚拟机配置和删除冗余存储容器等任务的自动化控制可以通过Powershell cmdlet、RESTful API或Azure管理门户提供的UI来实现。但是,在代码中自动化这些任务的最佳方法是什么?Fluent Management提供了一种.Net友好的方式来实现这些任务以及更多。这对于本项目尤其具有吸引力,因为我们已经开发了一个作业调度引擎,而Fluent Management将完美地融入其中。我们只需创建IJob,创建将工作进程配置到云端的代码,并根据需要安排它们触发。这正是接下来将要演示的。
首先,我们声明一个辅助方法来封装部署过程
public static async Task DeployAzureWorkerAsync(
string name,
string roleName,
string cspkgEndPoint,
X509Certificate2 cert,
string subscriptionId,
DeploymentSlot deploymentSlot,
string location,
int instanceCount)
{
await Task.Run(() =>
{
//get an azure friendly name
var storageName = new RandomAccountName().GetPureRandomValue();
//deploy storage (used to host worker process)
var subscriptionManager = new SubscriptionManager(subscriptionId);
subscriptionManager.GetStorageManager()
.CreateNew(storageName)
.AddCertificateFromStore(cert.Thumbprint)
.WithDescription(name)
.WithLocation(location)
.Go()
.Commit();
//deploy worker process
var deploymentManager = subscriptionManager.GetDeploymentManager();
deploymentManager
.AddCertificateFromStore(cert.Thumbprint)
.ForNewDeployment("deployment" + storageName)
.SetCspkgEndpoint(cspkgEndPoint)
.WithNewHostedService(name)
.WithStorageAccount(storageName)
.AddDescription("automated deployment" + name)
.AddEnvironment(deploymentSlot)
.AddLocation(location)
.AddParams(DeploymentParams.StartImmediately)
.ForRole(roleName)
.WithInstanceCount(instanceCount)
.WaitUntilAllRoleInstancesAreRunning()
.Go()
.Commit();
});
}
以及用法
/// <summary>
/// Running inside of a Quartz.net IJob
/// </summary>
public override async Task OnExecute(IJobExecutionContext context)
{
//define where to deploy to
var locationsToDeploy = new List<string>()
{
LocationConstants.EastAsia,
LocationConstants.NorthEurope,
LocationConstants.WesternEurope,
LocationConstants.WestUS,
LocationConstants.EastUS
};
//set the end point - this is the directory in which your packaged worker process was outputted to
string endPoint = @"[The root directory of your project packages ]";
//your azure subscription ID
var subscriptionId = "[You Azure Subscription ID - get this from .publishsettings]";
//Open the publish settings (you can download these from the Azure Management Portal)
using (var reader = new StreamReader(@"D:\Dev Apps\PublishSettings\settings.publishsettings"))
{
//extract an X509 certificate for security validation
string xml = reader.ReadToEnd();
var cert = PublishSettingsExtractor.AddPublishSettingsToPersonalMachineStore(xml);
//for every location specified, sequentially deploy a cloud service.
foreach (var location in locationsToDeploy)
{
//get an azure friendly name for the deployment
var nodeManage = new RandomAccountName();
//deploy
await DeploymentHelper.DeployAzureWorkerAsync(
name: "datagather" + locationsToDeploy.IndexOf(location),
roleName: "EventProcessing",
cspkgEndPoint: endPoint,
cert: cert,
subscriptionId: subscriptionId,
deploymentSlot: DeploymentSlot.Production,
location: location,
instanceCount: 1);
}
}
}
当此作业执行时,它将遍历可用位置并部署一个工作进程。每个工作进程都在虚拟机中运行,因此必须首先分配一个存储容器。
如果您想知道为什么我们部署到5个不同的数据中心,那是因为我们希望在查询Facebook API时尽可能多地使用IP地址,以避免被阻止。来自同一IP地址的请求过多会导致节流,从而限制我们导入过程的吞吐量。对于不同的解决方案,通常首选从同一位置/数据中心运行多个进程。
队列处理模式

如果您以前没有开发过基于云的处理,那么左侧的图将是您最熟悉的。我们有一个单线程进程,它获取数据、进行一些处理并存储结果——也许供用户以后查看。通常,这种模式对于可以快速处理的小量数据来说效果很好。
但是,如果我们处理的数据量更多呢?如果我们有数十万条记录需要处理,并且每条记录的处理都需要一段时间呢?一种方法是获取更好的硬件——也许您想要一台更好的服务器来应对额外的负载。

问题在于,在某个阶段,您将需要向外扩展,而不是向上扩展。您要么会耗尽处理能力,并且需要增加硬件中的核心数量,迫使您使用多线程来利用额外的功能——或者您可能会选择拥有多个服务器并将工作负载分配到每个服务器上。这就是队列发挥作用的地方,它非常适合Azure,因为我们可以初始化多个虚拟机来处理额外的负载。
您可以将队列想象成一个共享的待办事项列表,但它具有特殊功能,允许将待办事项列表条目锁定给一个人。让我们暂时不考虑队列的生活,您可能会选择让您的服务器访问一个包含需要处理的数据列表的SQL表,但是您如何确保服务器不会开始访问和处理完全相同的数据列表呢?如果服务器同时启动,那么如果没有某种复杂的并发锁定系统,很可能会导致每个服务器都存储相同的结果,从而否定了扩展的初衷。
队列以优雅的方式解决了这个问题。当一个工作进程访问队列中的消息时,该消息会在一小段时间内被隐藏。这给了工作进程处理消息的时间,并防止任何其他工作进程访问和处理重复数据。
还有一点需要注意——队列是轻量级的,并且针对执行速度进行了优化。这意味着它们只处理小消息,并且通常对可以添加的消息大小有限制。对于CityPulse,我们只需要添加eid或URL,但对于其他情况,只添加ID或键到消息中,然后将较大的实际有效负载保存在Blob存储或SQL行中,以便工作节点检索,这可能是有益的。

在上面的队列中,如果工作进程5 & 6同时请求消息,则基于队列的设计将确保一个工作进程获得消息7,另一个工作进程获得消息8。然后,这些消息将被锁定,其他工作进程无法访问。
QueueReaderSessionBase
我们云中的大多数工作进程都使用队列来管理和扩展工作负载。为了封装一些通用功能,如发送消息到其他队列、日志记录、处理API密钥问题(参见工作进程B),我们创建了一个抽象类供工作进程继承。
工作进程代码
 工作进程A - 原始活动收集
工作进程A - 原始活动收集
此工作进程负责爬取Facebook的活动ID,以便将它们添加到处理队列中,并最终添加到活动数据库。

活动ID(在此称为eid)是Facebook活动的唯一标识符,对于我们在使用Facebook API(FQL)将eid转换为有意义的信息的工作进程B尤其重要。
数据流

添加到搜索位置队列
在图的顶部,进程以CityPulse管理员或计划的任务开始,将初始URL列表添加到搜索位置队列。
添加队列可以通过.net与Azure SDK结合使用,或通过RESTFUL Web服务实现。我们将演示Azure SDK方法。
string[] urls = new[]
{
"http://facebook.com/myurl",
"http://facebook.com/myur2",
"http://facebook.com/myurl3"
};
string storageAccountUrl = "Your provided Azure Storage URL";
string queueName = "dataimporter1";
CloudStorageAccount account = CloudStorageAccount.Parse(storageAccountUrl);
CloudQueueClient queueClient = account.CreateCloudQueueClient();
CloudQueue queue = queueClient.GetQueueReference(queueName);
queue.CreateIfNotExist();
Parallel.ForEach(QueueHelper.SplitInto64K(urls), url =>
{
_queue.AddMessage(new CloudQueueMessage(url));
});
首先,我们创建一个存储帐户和一个队列客户端,使用在Azure中创建新存储帐户时提供的存储帐户URL。
然后,我们获取我们的队列(如果不存在,则创建一个新队列)。
最后,我们将URL作为消息推送到队列中。我们倾向于避免上传大量小消息,因为访问、读取和删除操作会产生一些性能开销。Azure目前限制队列消息为64K,因此QueueHelper.SplitInto64K(urls)用于将消息连接成CSV格式。这意味着我们的三个URL被压缩成一条消息。我们使用任务并行库的Parallel.ForEach来加速操作并并行推送消息——这对于大量消息尤其有用。
运行此代码后,我们可以通过编写简单的方法或测试来检查它是否已成功将消息推送到队列——但我更喜欢使用存储浏览器。有几个浏览器可供选择,但我使用的是Azure Storage Explorer(azurestorageexplorer.codeplex.com)。通过下载该应用程序并输入我的存储帐户详细信息,我们可以看到队列的内容,并且可以看到URL已被连接并添加。

从搜索位置队列读取
利用我们的导入应用程序和Quartz.net,我们可以安排一个作业在世界各地的Azure数据中心启动此工作进程,并根据添加到队列中的URL数量,利用并行计算来满足任何规模的需求。
public class RawEventImporterQueueSession : QueueReaderSessionBase
{
private readonly RawEventContext _dbContext;
private bool _continue = true;
private List<string> _addedSearchTermsToBuffer = new List<string>();
public int ImportedCount { get; set; }
public RawEventImporterQueueSession(RawEventContext dbContext, string queueUrl, string queueName)
: base(queueUrl, queueName)
{
//the event import database (code first EF will be covered later in the article)
_dbContext = dbContext;
}
public override async Task StartAsync()
{
try
{
while (_continue)
{
//this will pull 40 events
List<CloudQueueMessage> urlsToSearch = this.DeQueueEvents(1).ToList();
if (urlsToSearch.Any())
{
//start by deleting the messages
this.DeleteEvents(urlsToSearch);
//get urls
IEnumerable<string> splitUrls = this.GetCommaSeperated(urlsToSearch);
//inform import database that we are gathering
RecordResults();
//Save the URLs in the import database
//(this will us to block certain URLs that do not provide results)
var urls = splitUrls.Select(x => _dbContext.GetOrCreateURL(x));
//start the gathering process (an encapsulation of the actual website crawling)
var session = new EventGatheringSession(_dbContext, urls.ToList());
session.ExtractedEventIds += (facebookEvents) =>
{
//we have found some events!
ImportedCount += facebookEvents.Count();
//add to buffer which pushes the eids to the event processor queue
AddToImportedBuffer(facebookEvents.Select(x => x.Id));
//inform if a URL resulted in eids or not, block non relevent URLs
UpdateURLs(facebookEvents);
};
await session.StartAsync();
//we have completed this batch, sleep as to throttle the server
Thread.Sleep(2500);
}
else
{
//nothing in the queue, stop processing and shut down
_continue = false;
}
}
}
catch (Exception queueException)
{
//we have encountered an error, log so it can be analysed after the processing is complete
ImportException exception = new ImportException();
exception.ExceptionString = "Raw Event Import Queue Exception : "
+ queueException.Message;
exception.ExceptionStackTrace = queueException.StackTrace;
var rawExceptionContext = new RawEventContext();
rawExceptionContext.ImportExceptions.Add(exception);
rawExceptionContext.SaveChanges();
}
}
private void AddToImportedBuffer(IEnumerable<string> eids)
{
_toImportBuffer.AddRange(eids);
//if the buffer is full, add to the event processor queue asyncronously
if (_toImportBuffer.Count > 30)
{
Task.Run(() =>
{
this.AddMultipleToOtherQueue(Settings.Default.EventProcessingQueueName,
_toImportBuffer);
_toImportBuffer.Clear();
});
}
}
}
处理完成后,并且eid已添加到工作进程B的队列中——VM将被关闭并从生产环境中移除,以避免产生任何额外的Azure计费模型成本。
 工作进程B - EID处理
工作进程B - EID处理
一旦工作进程A提取了eid并将其添加到原始活动处理队列中,消息将如下所示

工作进程B的目标:将eid转换为包含所需所有信息的有意义的活动。
Facebook FQL
Facebook FQL(Facebook查询语言)是一种API,允许应用程序使用类似SQL的语法与Facebook中的对象进行交互。这就是我们将用于提取活动信息的内容。
一旦您注册成为Facebook开发者,并向他们注册了应用程序,您将获得一个OAuth认证令牌,您可以使用它来查询他们的API(指南在此)。通过访问Facebook工具浏览器,我们可以使用Facebook提供的一个很棒的工具来实时查询其API——这对于调试或调查API操作非常有用。
假设我们有一个公共事件eid,我们想通过FQL解析它。该eid是
162478390590630
通过研究Facebook FQL参考文档,我们可以推断出检索此事件所需信息的FQL将是
SELECT eid, name, start_time, description, end_time, attending_count, declined_count, venue, timezone, version, all_members_count, update_time FROM event WHERE eid = 162478390590630

这将返回一个JSON对象,代表事件及其部分信息。我们在此可以看到,有一个事件将于6月28日开始,目前有39人计划参加。
但是我们缺少了一样东西。还记得我们总体的目标吗?那就是提取Facebook活动并在地图上显示它们。我们需要经纬度。
此事件的场馆ID为10647924275034,我们可以用它来解析地理坐标。
这次的FQL是
SELECT page_id, type, were_here_count,location.latitude, location.longitude FROM page WHERE page_id IN (SELECT venue.id FROM #event_info)
这将返回JSON对象
{
"data": [
{
"eid": 162478390590630,
"name": ">* Dub Theories - Part 2 ! *<",
"start_time": "2013-06-28T09:00:00+0100",
"description": "DUB THEORIES RETURNS FOR PART 2...\n''SHOWCASING DUB INFLUENCED
PRODUCTIONS''\n\n
***FRIDAY 28TH OF JUNE @ Cosies! ONLY £3***\n
*REGGAE DUB & JUNGLE*\n\n-> DUB INVASION (Live mix!)\n(Silverback recordings!)
\n\n-> MESSENJAH YOUTH\n(Swindon massive!)\n\n-> JONNY FISHA\n(Dubwise
theorist!)\n\n
-> J - MAN\n(Badman Junglist!)\n",
"end_time": null,
"attending_count": 39,
"declined_count": 22,
"venue": {
"id": 106479242750341
},
"timezone": "Europe/London",
"version": 2,
"all_members_count": 757,
"update_time": 1370464550
}
]
}
我们可以进行最后一次优化,目前为了获取所需信息需要进行2次API调用,但Facebook会限制API调用次数,这将限制我们可以连续进行的API调用次数。通过使用FQL批量查询,我们可以将此操作合并为一次FQL调用,然后将结果序列化为单个Json对象。
这的FQL将是
{"event_info":"SELECT eid, name, start_time, end_time, attending_count, declined_count, venue, timezone, version, all_members_count, update_time FROM event WHERE eid = 162478390590630","event_venue":"SELECT page_id, type, were_here_count,location.latitude, location.longitude FROM page WHERE page_id IN (SELECT venue.id FROM #event_info)"}
这将返回一个代表结果数组的单个json对象(一个用于事件,一个用于其场馆)
{
"data": [
{
"name": "event_info",
"fql_result_set": [
{
"eid": 162478390590630,
"name": ">* Dub Theories - Part 2 ! *<",
"start_time": "2013-06-28T09:00:00+0100",
"end_time": null,
"attending_count": 39,
"declined_count": 22,
"venue": {
"id": 106479242750341
},
"timezone": "Europe/London",
"version": 2,
"all_members_count": 757,
"update_time": 1370464550
}
]
},
{
"name": "event_venue",
"fql_result_set": [
{
"page_id": 106479242750341,
"type": "ARTS/ENTERTAINMENT/NIGHTLIFE",
"were_here_count": 1493,
"location": {
"latitude": 51.460999084183,
"longitude": -2.5862773472242
}
}
]
}
]
}
太棒了——我们拥有将这些对象存储到SQL所需的所有信息,以便为我们的网站用户提供。
首先,我们必须自动化这个过程,因为使用开发人员浏览器工具仅用于调试,并且对于我们集成到云工作进程中是不可持续的。
HttpClient
Facebook提供的FQL API响应HTTP请求,我们需要手动构建这些请求。我们还需要一个客户端来发送这些请求,这就是HttpClient发挥作用的地方。HttpClient是在.net Framework 4.5中引入的,非常适合发送HTTP请求并存储结果。
public event Action<RawEventProcessingResult> ProcessedEvent;
public async Task MakeFQLCall(string fql, string authToken)
{
//build URL
string url = "https://graph.facebook.com/fql?q=" + fql + "&format=json&access_token="
+ authToken;
//create client and call FQL
HttpClient client = new HttpClient();
var response = await client.GetAsync(url);
//get the response
var text = await response.Content.ReadAsStringAsync();
//deserialize the JSON into POCO objects
var results = JsonConvert.DeserializeObject<RawEventProcessingResult>(text);
//Signal to queue reader that we have extracted the event
ProcessedEvent(result);
}
RawEventProcessingResult是json结果的一个保存类。它的结构与json对象返回的结构完全相同,以便我们可以使用JsonConvert类将json反序列化为对象。
以下是json结果的对象层次结构

这并不是我们想要存储事件的格式,因此创建了一些更直观的类来保存事件信息。考虑到未来,我们创建了LiveEvent基类(与Facebook信息无关),其中包含FacebookLiveEvent,其中包含Facebook特定的数据。

以下是处理eid并存储返回事件的工作进程代码
public class EventProcessingQueueSession : QueueReaderSessionBase
{
private readonly ApiKeySession _apiSession;
private readonly ImportManagementContext _dbContext;
private LiveEventsContext _liveContext;
private List<EventCategory> _categories;
private bool _continue = true;
private EventProcessingSession _importSession;
private LiveEventsContext _liveEventsContext = new LiveEventsContext();
public EventProcessingQueueSession(ApiKeySession apiSession, ImportManagementContext dbContext,
string queueUrl,
string queueName)
: base(queueUrl, queueName)
{
_apiSession = apiSession;
_dbContext = dbContext;
_liveContext = new LiveEventsContext();
_categories = _liveContext.Categories.ToList();
}
public override async Task StartAsync()
{
try
{
while (_continue)
{
//retrieve block of eids in a comma seperated format
var messages = this.DeQueueMessages(1).ToList();
var idsToParse = this.GetCommaSeperated(messages);
if (idsToParse.Any())
{
//start an importing process to return event information from
//the Facebook FQL
_importSession = new EventProcessingSession(_liveContext,
_categories,
_apiSession.ApiKey.Key,
idsToParse.ToList());
_importSession.LiveEventProcessed += newEvent =>
{
//we have process a facebook event, store into the live database
FacebookLiveEvent fbEvent = newEvent;
_liveEventsContext.Events.Add(fbEvent);
//add the newly added live event ID so it can be categorised
this.AddToOtherQueue("categorisationQueue", newEvent.Id);
};
_importSession.ApiKeyBlocked += () =>
{
//the api key we are using for facebook has been temporary blocked due to
//throttling.this won't happen very often as we buffer the calls as to
// not strain the server, but handle anyway.
_continue = false;
this.NotifyApiBlocked();
};
await _importSession.StartAsync();
//delete the messages as we have processed them
this.DeleteMessages(messages);
_liveContext.SaveChanges();
Thread.Sleep(2000);
}
else
{
_continue = false;
}
}
}
catch (Exception queueException)
{
//an exception has been thrown, save details to the database so it can be investigated
ImportException exception = new ImportException();
exception.ExceptionString = "Event Processing Queue Exception : "
+ queueException.Message;
exception.ExceptionStackTrace = queueException.StackTrace;
var rawExceptionContext = new ImportManagementContext();
rawExceptionContext.ImportExceptions.Add(exception);
rawExceptionContext.SaveChanges();
}
}
}
此时,事件已添加到数据库,但我们仍然缺少最后一个要求。事件分类。
 工作进程C – 事件分类
工作进程C – 事件分类
Facebook上有很多音乐活动。相信我。俱乐部和夜生活推广者占主导地位,他们试图吸引每个学生或年轻人参加他们的娱乐活动。这对CityPulse的年轻学生用户来说很棒——但其他用户呢?他们可能对夜生活不感兴趣,但可以很好地利用这个工具发现他们所在地区本周末的节日或社区活动。
这就是事件分类发挥作用的地方,并且是应用程序的一个重要要求,但存在复杂性。Facebook不按此方式对活动进行分类,因此我们必须以更手动的方式进行分类。
我们创建了一个自定义人工智能组件来分析事件,以指示它可能属于哪个类别。
活动类别
- 音乐与夜生活
- 喜剧
- 戏剧与艺术
- 节日
- 家庭与社区
- 体育
- 展览与集市
- 社交与聚会
- 个人(隐藏)
这些是网站用户可以用来过滤事件的类别。有些事件被归类为个人(如Mike的21岁生日派对等),这些事件对网站是隐藏的。
人工智能的用武之地
一种简单的分类方法是列出将应用于每个类别的关键字列表。音乐与夜生活可能有“音乐”、“饮品”、“dub-step”和“reggae”,而体育可能有“比赛”、“场地”和“开球”。
这种方法的缺点是它远非全面。一个节日可能有大量与音乐相关的关键字,但这并不意味着它就是音乐与夜生活活动。一个夜总会可能有一个与场馆成立年份相关的“生日”,但这也不意味着它应该被归类为个人并从网站结果中隐藏。
我们选择的方法(与许多人工智能算法一样)是保持关键词列表的类似思路,但引入一个训练数据集和一个真实数据集。我们手动构建训练数据集,然后让算法接管,使用模糊逻辑来猜测“真实”数据集中的事件,并在其进展中更新关键词字典。
训练数据集
构建训练数据集是一个手动过程。CityPulse管理员将使用导入管理工具手动将明显的事件分类到相应的类别中,以构建计算机对每个类别的知识。
在每个类别添加了大约50个事件后,我们就有足够的信息来处理真实数据集。然后,每个类别都会分配一个关键词字典,这些关键词在分配给它的事件中最常出现。
我们可以使用以下代码查询每个类别的出现次数最多的事件
Dictionary<string, int> result = new Dictionary<string, int>();
//get category from live database
EventCategory liveCategory = new LiveEventsContext().Categories.Single(x => x.Name.Contains("Music"));
//use the import management database
using (var _dbContext = new ImportManagementContext())
{
//get a list of common words so they can be excluded from extraction
List<CommonWord> excluded = _dbContext.CommonWords.ToList();
//for every event in category, build up a list of occuring words
foreach (var anEvent in liveCategory.Events)
{
var extracted = KeywordExtractor.Extract(new[]
{
anEvent.Name,
anEvent.Description
}, excluded);
//add single extracted word list to 'result' list
foreach (var extract in extracted)
{
if (!result.ContainsKey(extract.Key))
{
result[extract.Key] = 0;
}
result[extract.Key]++;
}
}
}
foreach (var topKeyWord in result.OrderByDescending(x => x.Value))
{
Debug.WriteLine("Keyword {0} Occurs {1}", topKeyWord.Key, topKeyWord.Value);
}
结果如下:
Keyword band Occurs 8
Keyword music Occurs 7
Keyword sound Occurs 4
Keyword incredible Occurs 4
Keyword scene Occurs 4
Keyword debut Occurs 4
Keyword pub Occurs 3
Keyword feel Occurs 3
Keyword real Occurs 3
Keyword steve Occurs 3
Keyword folk Occurs 3
Keyword songs Occurs 3
还不错,这些确实是与音乐与夜生活相关的关键词。我们可以通过手动为该类别分配更多事件来做得更好。
您可能还注意到这一行代码
var excluded = _dbContext.CommonWords.ToList();
CommonWords是数据库中的一个表,包含“the”和“as”等常用词。这些词从关键词提取过程中排除,因为它们没有告诉我们关于事件的任何信息。它们是通过手动添加术语和提取所有事件中出现的词的混合模型创建的。
让我们看看“家庭与社区”类别。我们只需要改变
var liveCategory = new LiveEventsContext().Categories.Single(x => x.Name.Contains("Family"));
结果如下:
Keyword charity Occurs 64
Keyword raise Occurs 26
Keyword good Occurs 13
Keyword aid Occurs 12
Keyword raffle Occurs 12
Keyword family Occurs 11
Keyword cancer Occurs 11
Keyword show Occurs 10
Keyword music Occurs 10
Keyword band Occurs 8
Keyword entertainment Occurs 7
Keyword inn Occurs 7
Keyword holding Occurs 7
Keyword funds Occurs 7
Keyword team Occurs 7
也许有点过于偏向慈善活动,但我们以后可以通过添加更多来自其他类型社区活动的条目来解决这个问题。
“真实”数据集
这就是算法发挥作用的地方,我们让自动化接管。我们使用训练集关键字字典,让计算机根据其最佳判断来决定一个事件可能属于哪个类别。如果它无法确定正确的类别,它会继续进行;如果可以,它会将事件分配到正确的类别,并更新包含该事件关键词的字典。
因此,随着我们继续进行分类过程,匹配度会随着时间的推移而提高。
算法的伪代码如下
For 1.. n events
extract event keywords
compare against each categories keyword dictionary
if 1 or more categories keywords match over a certain threshold value
add event and update category keywords
else
Add event to ‘social & meetups’
continue
请注意,如果一个事件无法分类,它将被添加到“社交”类别。这将确保事件仍然显示在网站地图上。
分类工作进程代码
public class CategorisationQueueSession : QueueReaderSessionBase
{
private bool _continue = true;
private readonly LiveEventsContext _liveEventContext = new LiveEventsContext();
public CategorisationQueueSession(string queueUrl, string queueName)
: base(queueUrl, queueName)
{
}
public override async Task StartAsync()
{
while (_continue)
{
//get the live database event block
IEnumerable<CloudQueueMessage> messages = this.DeQueueMessages(5);
var liveEventIds = this.GetCommaSeperated(messages);
//grab the actual events in the message from the live database
List<FacebookLiveEvent> liveEvents = new List<FacebookLiveEvent>();
foreach (var liveEventId in liveEventIds.Select(x=>int.Parse(x)))
{
liveEvents.Add(_liveEventContext.Events.OfType<FacebookLiveEvent>()
.SingleOrDefault(x=>x.Id == liveEventId));
}
//run the categorisation session, start by injecting the non hidden categories
var nonHiddenCategories = _liveEventContext.Categories.Where(x=>x.Name != "Personal");
var runCategorisationSession = new CategorisationSession(nonHiddenCategories);
runCategorisationSession.Categorised += (categories, liveEvent) =>
{
//we have categorised an event, update the database row
foreach (var matchedCategory in categories)
{
liveEvent.Categories.Add(matchedCategory);
}
};
//start the process
await runCategorisationSession.StartCategorisationsAsync(new ImportManagementContext(),
liveEvents);
//categorisation ended for these events, update the database
_liveEventContext.SaveChanges();
}
}
}
结果

算法在分类方面似乎做得很好。特别令人满意的是它对事件——“Dagenham Dog Soldiers Bike and Band Night”的处理。它同时被归类为“家庭与社区”和“音乐与夜生活”,考虑到它有乐队表演,但主要是慈善活动。
回顾
至此,Azure导入过程就告一段落了。回顾一下,我们已经
- 爬取了Facebook的活动ID
- 将活动ID添加到EID处理队列
- 使用Facebook的FQL API将活动ID处理成真实活动
- 将活动存储在实时活动数据库中
- 将数据库ID添加到分类队列
- 使用自定义人工智能算法对活动进行分类
存储
Entity Framework Code First
抽象化维护持久化数据访问层的复杂性对任何开发人员都极具吸引力,因为我们可以花更多时间编写应用程序,而不是编写围绕任何标准CRUD操作的样板代码。CityPulse解决方案中的数据库是通过Entity Framework (EF) Code-First模型创建的。EF的Code First变体允许我们使用普通的C#对象(POCO对象)来建模实体及其关系。在运行时,EF库将构建模型,并在必要时为我们创建数据库。这赋予的强大之处在于,作为开发人员,我们实际上不必离开.net世界。
Linq-to-Entities允许我们与数据库进行交互,而无需编写SQL,从而再次减小了数据访问层的规模和复杂性。
深入研究Entity Framework Code First超出了本文的范围,但如果您是该概念的新手,那么本文绝对值得一读。
Code First with Entity Framework 5
根据主架构图,我们将使用两个主要数据库在云中存储信息。
导入管理数据库
此数据库用于所有与导入相关的内容。最终用户永远不会看到此数据库,因为它由Import Management WPF Tool和Azure中的Worker Processes使用。抓取的URL、统计信息、API密钥、报告、异常和日志都存储在此处,以便用于调查导入过程中可能出现的任何复杂情况。常用词或特定于类别的词也存在于此,以帮助Worker Process C中的分类算法。

实时活动数据库

实时活动数据库主要由网站使用。它存储实时活动以及活动所属的任何类别。
Code-first在Azure中的生成和更新
Azure中的Code-first非常容易,并且不需要任何超出Azure常规用法的变体。一旦将连接字符串添加到app/web.config中,应用程序就可以开始与数据库交互。Code-first迁移的处理方式也相同,只需使用Visual Studio内置的Package Manager即可。
PM > Enable-Migrations
此命令创建一个配置文件,我们可以使用它来控制部署迁移时的特定用例。我们可以将其用于种子数据,或使用Fluent Api来描述模型中存在的关系。
以下是使用Code-First迁移添加存储“Feedback”条目到我们数据库的演示,供用户发送他们意见给网站创建者使用。
在迁移之前,数据库看起来是这样的:

这是代码模型的状态:
public class LiveEventsContext : DbContext
{
public DbSet<LiveEvent> Events { get; set; }
public DbSet<EventCategory> Categories { get; set; }
}
我们将从创建一个POCO形式的反馈实体开始。
public class SiteFeedback
{
public int Id { get; set; }
public DateTime Created { get; set; }
public string Description { get; set; }
public string Email { get; set; }
}
创建一个名为Id的属性,允许Entity Framework在模型转换为SQL表时推断出它是主键。我们可以使用属性上的[Key]属性来明确说明这一点,但EF足够智能,知道Id字段是键。
让我们将其添加到模型中:
public class LiveEventsContext : DbContext
{
public DbSet<LiveEvent> Events { get; set; }
public DbSet<EventCategory> Categories { get; set; }
public DbSet<SiteFeedback> Feedback { get; set; }
}
通过创建DbSet<T>集合并将其类型化为我们的新实体,我们表示打算将此实体类型映射到数据库表。
现在我们可以创建一个迁移文件以在数据库上运行,只需在Package Console Manager中键入以下命令:
Add-Migration addFeedbackMigration
这将自动生成一个迁移文件并在Visual Studio中打开它。
public partial class addFeedback : DbMigration
{
public override void Up()
{
CreateTable(
"dbo.SiteFeedbacks",
c => new
{
Id = c.Int(nullable: false, identity: true),
Created = c.DateTime(nullable: false),
Description = c.String(),
Email = c.String(),
})
.PrimaryKey(t => t.Id);
}
public override void Down()
{
DropTable("dbo.SiteFeedbacks");
}
}
现在,在Package Console Manager中运行命令:
PM > Update-Database
结果是我们预期的数据库更新。

网站
网站是CityPulse用户与应用程序交互的方式。在他们连接之前,Azure导入过程已经完成了它的工作,我们将会拥有大量分类的活动,可在地图上可视化。地图是解决方案的“公共”元素,也是将所有内容联系在一起的部分。让我们看看它是如何工作的。
技术
对于网站,我们选择了ASP.net MVC4来提供HTML到浏览器,以及Web API来以json格式提供活动。为了获得最佳的用户体验,网站主要充当单个页面应用程序,因此在很大程度上依赖于javascript来渲染前端。
提供活动 – Web API
ASP.net Web API提供了一种快速便捷的方式来提供RESTful Web Services。虽然REST(Representational State Transfer)一词涵盖了多种原则——但对我们来说,这意味着良好的可访问性。Web API实现没有平台特定的依赖项,因此我们可以从手机和桌面访问该技术,无论在哪里。
这样做的缺点是,没有像WCF这样的技术那样用于数据传输对象的客户端代码生成——但我们认为这是一个可以接受的权衡。Web API也是无状态的,这使我们能够轻松地将其扩展到更高的负载。
让我们来看看如何编写将提供我们活动的API控制器。
事件API控制器
我们可以从添加控制器开始,通过Database-First Entity Framework上下文与实时数据库建立连接,我们称之为LiveEventsEntities。值得注意的是,这已在Controllers/api/EventsController中创建。/api/部分不是必需的,但如果希望在一个站点中运行,它有助于将其与常规MVC控制器分开。
作为基本要求,我们将希望通过提供所请求事件的ID来传递特定事件的信息。
public class EventsController : ApiController
{
/// <summary>
/// Queryable storage of the live event table.
/// - IQueryable as to not load the entire table into memory in the constructor
/// </summary>
private IQueryable<LiveEvent> _liveEvents;
public EventsController()
{
//create an instance of the database context
var liveEventContext = new LiveEventsEntities();
//The WebApi doesn't like to serialize dynamic proxy objects, turn off lazy loading
liveEventContext.Configuration.LazyLoadingEnabled = false;
liveEventContext.Configuration.ProxyCreationEnabled = false;
//lazy loading is disabled so manually load in the categories
//so they get delivered in the results too
_liveEvents = liveEventContext.LiveEvents.Include("EventCategories");
}
/// <summary>
/// Retrieve an event by its Id
/// </summary>
public HttpResponseMessage Get(int id)
{
var foundEvent = _liveEvents.SingleOrDefault(x => x.Id == id);
if (foundEvent == null)
{
return Request.CreateErrorResponse(
HttpStatusCode.NotFound,
String.Format("Event {0} wasn't found", id);
}
return Request.CreateResponse(HttpStatusCode.OK, foundEvent); ;
}
}
HttpResponseMessage Get(int id)是这里的关键,也是网站将用于检索事件信息的内容。路由引擎负责访问此方法,该方法将通过HTTP请求到/api/Event/{event id}来访问。
这里还有几点需要注意,首先是动态代理对象的处理。为了启用json序列化,如果EF实体被用作返回对象或嵌入在HttpResponseMessage中,则必须关闭动态代理(在EF中启用延迟加载)。
其次,HttpResponseMessage本身——它不是真正必需的,因为我们可以直接返回LiveEvent,但它被认为是最佳实践,因为我们可以利用HttpStatusCode并按照其设计方式来使用Http。
最后,上述代码默认会返回xml。为了确保只返回json,请将以下代码添加到WebApiConfig.cs类中。
//ensure only json is returned from the Api
var appXmlType = config.Formatters.XmlFormatter.SupportedMediaTypes.FirstOrDefault(t =>
t.MediaType == "application/xml");
config.Formatters.XmlFormatter.SupportedMediaTypes.Remove(appXmlType);
运行站点后,我们可以查询API以确保它返回事件信息。Fiddler是一个很棒的Web调试工具(fiddler2.com),我们可以用它来查看结果。
一个请求:
https://:8671/api/events/3
结果是json回复:
{
"Id": 3,
"Name": "Hip Route",
"Description": "“Hip Route have a universal sound that should appeal to all lovers of real music”,
"ImageNormal": "https://profile-a.xx.fbcdn.net/hprofile-ash4/261164_136561216508726_1794165337_s.jpg",
"ImageSmall": "https://profile-a.xx.fbcdn.net/hprofile-ash4/261164_136561216508726_1794165337_t.jpg",
"ImageCoverUrl": null,
"Start": "2013-12-21T21:00:00",
"End": null,
"Updated": null,
"Longitude": -1.74417424,
"Latitude": 51.54513,
"Street": null,
"City": null,
"State": null,
"Country": null,
"Zip": null,
"Created": "2013-06-09T15:16:27.57",
"IsHidden": false,
"FacebookId": "136561216508726",
"AttendingCount": 7,
"InvitedCount": 399,
"FacebookPrivicyType": 1,
"Discriminator": "FacebookLiveEvent",
"EventCategories": [{
"Id": 1,
"Name": "Music & Nightlife"
}]
}
很好,这可以正常工作。不过,下一个要求稍微复杂一些:
当我们提供一些地理坐标、开始日期和结束日期时,我们希望返回所有符合该条件的事件。
地理坐标可以通过获取用户地图的边界来建模,以纬度和经度为单位。
开始日期和结束日期允许我们提供事件过滤器,以便用户可以看到今天或本周末发生的活动。
代码如下:
/// <summary>
/// Retrieve an event by specifying geocoordinates
/// </summary>
[HttpGet]
public HttpResponseMessage Get(DateTime startTime, DateTime startEndTime, float neLat, float neLong, float swLat, float swLong)
{
try
{
var foundEvents = _liveEvents.Where(liveEvent =>
liveEvent.Start >= startTime &&
liveEvent.End <= startEndTime &&
liveEvent.Longitude >= swLong && liveEvent.Longitude <= neLong &&
liveEvent.Latitude >= swLat && liveEvent.Latitude <= neLat);
return Request.CreateResponse(HttpStatusCode.OK, foundEvents);
}
catch (Exception e)
{
return Request.CreateErrorResponse(HttpStatusCode.NotFound, e);
}
}
这次请求需要更多的参数,但仍然可以由同一定义的路由处理。现在通过请求:
//Area in London on the week starting 16th June Events? startTime=2013-06-16T23:00:00.000Z& startEndTime=%202013-06-23T22:59:59.000Z& neLat=51.5195& neLong=-0.143411& swLat=51.506520& swLong=-0.184609
我们收到如下响应:

API返回了一个匹配该位置的多个事件列表,太棒了!但要利用这个新API,首先,我们必须在客户端呈现一些UI。
延伸阅读
客户端Google地图与Typescript
要在用户浏览器上显示新检索到的事件,我们需要完成以下任务:
- 1. 使用Google API加载Google地图。
- 2. 响应用户与地图的交互(用户平移、用户缩放)。
- 3. 获取地图的当前边界(纬度和经度)并使用上面演示的调用查询API。
- 4. 反序列化json响应到事件,并将它们作为标记添加到地图上。
为了实现这一点,我们将大量使用Typescript、Html和Javascript。
Typescript
Typescript是微软的杰作,它通过提供可选的静态类型和基于类的面向对象编程来扩展javascript。这意味着作为开发人员,由于大多数常用javascript库都提供了类型定义,因此我们在Visual Studio中获得了出色的智能感知支持。这意味着花更少的时间在第三方网站上查找API,花更多的时间编写代码。此外,从维护的角度来看,使用命名空间要容易得多,这可以很好地配合像CityPulse这样严重依赖javascript的解决方案。
对于那些仍然喜欢javascript并希望继续享受该语言动态特性的开发者来说,请欢欣鼓舞:javascript可以与typescript和谐地开发,因为它们在底层都可以编译成javascript。这使我们能够获得静态类型的好处,但只在我们想要的时候。
显示Google地图
首先,我们在Visual Studio中创建一个标准的Asp.net MVC4应用程序。确保我们已安装typescript插件,让我们开始创建一个mapManager。将代码抽象到模块中,而不是将所有内容都放在页面底部,通常是个好主意——尤其是在一个可能使用大量类型/javascript的Web应用程序中。Typescript使这一点特别容易,因为类会被转换为常用的javascript设计模式——一个揭示模块。
开始在Scripts/lib/mapManager.ts下创建一个typescript文件。
//Make sure we have the google typings referenced or we wont get intellisense
/// <reference path="../../typings/google.maps.d.ts" />
module My {
export class mapManager {
_map: google.maps.Map;
constructor () { }
public init() {
//standard options, center the map over the world by default
var mapOptions = {
center: new google.maps.LatLng(30.23804, -70),
zoom: 3,
panControl: false,
streetViewControl: false,
maxZoom : 18,
minZoom : 2,
mapTypeControl: false,
zoomControlOptions: {
position: google.maps.ControlPosition.RIGHT_CENTER
},
mapTypeId: google.maps.MapTypeId.ROADMAP
};
//create map on the canvas
this._map = new google.maps.Map(document.getElementById("map_canvas"),
mapOptions);
}
}
}
注意对Google地图类型定义的引用。由于Google地图是一个javascript实现,因此必须将静态类型定义附加到库中。您可以使用Visual Studio中的Nuget包管理器来下载它们。
PM> Install-Package google.maps.d.ts
接下来,我们可以创建html图表元素并初始化管理器。
当设置MVC4应用程序时,Visual Studio通常会为我们创建一个Home/Index.html视图供我们使用。清除其中的标准内容并添加:
<div id="map_canvas" style="width: 100%; height:100%;"></div>
<script type="text/javascript">
$(document).ready(function () {
//initialise the map manager
var mapManager = new My.mapManager();
mapManager.init();
});
</script>
这个jQuery函数ready会等到页面加载完毕,找到来自我们typescript文件的、由javascript生成的mapManager,并对其进行初始化。
最后,我们确保Layout.cshtml文件中引用了所有正确的脚本。
<script src="https://maps.googleapis.com/maps/api/js?v=3.exp&sensor=true"></script> <script type="text/javascript" src="http://maps.googleapis.com/maps/api/js?libraries=places&sensor=true"></script> <script src="~/Scripts/lib/mapManager.js"></script>
使用MVC4的一个好处是它能够打包脚本并对其进行最小化。上面的例子为了简洁起见没有这样做,但打包和最小化可以混淆代码并提高浏览器加载时间。请参阅ASP.NET MVC4:打包和最小化。
请注意,mapManager引用了mapManager.js文件,这是typescript在保存时转换为的已编译javascript。

好了!我们有一个工作的地图!
让我们继续在地图上挂钩一些事件,以便在用户输入时将信息传递给我们的API。
public init() {
var self = this;
//(code suppressed) Create map
google.maps.event.addListener(this._map, 'zoom_changed', () => {
self.loadEvents();
});
google.maps.event.addListener(this._map, 'mouseup', () => {
self.loadEvents();
});
}
public loadEvents() {
//get bounds of map viewport
var bounds = this._map.getBounds();
//get events for the next week
var today = new Date();
var weekFromNow = new Date();
weekFromNow.setDate(today.getDate() + 7);
//create url request to Api
var jsonRequest =
"/api/Event?" +
"startTime=" + today.toISOString() +
"&startEndTime= " + weekFromNow.toISOString() +
"&neLat=" + bounds.getNorthEast().lat() +
"&neLong=" + bounds.getNorthEast().lng() +
"&swLat=" + bounds.getSouthWest().lat() +
"&swLong=" + bounds.getSouthWest().lng();
//just log to console for now
console.log(jsonRequest);
}
我们创建了一个函数,该函数检索地图的当前视口并构建一个API请求,该请求以Json格式构建并发送到服务器。这可以使UI保持响应,因为没有完整的页面回发。
在将日期对象发送到webApi之前,会调用toISOString()函数。这会将它们保持为可以直接注入到api控制器参数列表中的格式。
按F5运行代码,并稍微移动地图,将在浏览器控制台中显示以下内容:
/api/Event?startTime=2013-06-21T07:19:22.775Z&startEndTime= 2013-06-28T07:19:22.775Z&neLat=78.54&neLong=180&swLat=-49.8820&swLong=-180 /api/Event?startTime=2013-06-21T07:19:33.819Z&startEndTime= 2013-06-28T07:19:33.819Z&neLat=71.72&neLong=180&swLat=-6.38316&swLong=-180 /api/Event?startTime=2013-06-21T07:19:34.421Z&startEndTime= 2013-06-28T07:19:34.421Z&neLat=59.38&neLong=91.19&swLat=18.3684&swLong=-94.60 /api/Event?startTime=2013-06-21T07:19:34.645Z&startEndTime= 2013-06-28T07:19:34.645Z&neLat=50.64&neLong=48.037&swLat=29.7178&swLong=-44.86 /api/Event?startTime=2013-06-21T07:19:36.777Z&startEndTime= 2013-06-28T07:19:36.777Z&neLat=60.34&neLong=42.80&swLat=43.47777&swLong=-50.09 /api/Event?startTime=2013-06-21T07:19:38.185Z&startEndTime= 2013-06-28T07:19:38.185Z&neLat=57.65&neLong=19.45&swLat=49.43960&swLong=-26.99 /api/Event?startTime=2013-06-21T07:19:38.414Z&startEndTime= 2013-06-28T07:19:38.414Z&neLat=55.95&neLong=7.761&swLat=51.87276&swLong=-15.46 /api/Event?startTime=2013-06-21T07:19:38.953Z&startEndTime= 2013-06-28T07:19:38.953Z&neLat=55.07&neLong=1.916&swLat=53.032449&swLong=-9.69
现在我们只需要将它们发送到api控制器,并读取响应——为我们返回的每个事件添加地图标记。
将事件加载到地图作为标记
为了获取WebAPI的结果,并添加事件集合(以json表示),我们需要对代码进行一些修改。
public loadEvents() {
var thisObject = this;
//clear any existing markers
this.clearEvents();
//get bounds of map viewport
var bounds = this._map.getBounds();
var today = new Date();
var weekFromNow = new Date();
weekFromNow.setDate(today.getDate() + 7);
//create url request to Api
var jsonRequest =
"/api/Events?" +
"startTime=" + today.toISOString() +
"&startEndTime= " + weekFromNow.toISOString() +
"&neLat=" + bounds.getNorthEast().lat() +
"&neLong=" + bounds.getNorthEast().lng() +
"&swLat=" + bounds.getSouthWest().lat() +
"&swLong=" + bounds.getSouthWest().lng();
//make ajax request to the server
$.getJSON(jsonRequest, (eventCollection) => {
//response received, iterate events
$.each(eventCollection, (index, event) => {
//add each event as a map marker
thisObject.addEventToMap(event);
});
});
}
我们没有将API请求输出到控制台窗口,而是创建了一个AJAX请求到服务器。$.getJson()是一个异步函数,它需要一个回调函数,该函数在该函数中迭代结果并调用我们自己的addEventToMap函数。我们可以从下面的屏幕截图中看到服务器结果的构成,该截图是从Google Chrome浏览器中的开发人员工具捕获的。
注意,浏览器只会显示来自typescript文件的已编译javascript,这由显示文件上的.js扩展名表明。

另请注意,返回的数组大小为100。这是因为我们限制了可以从服务器返回的事件数量。撰写本文时,我们的LiveEvents数据库中有超过10万个事件。即使通过地理定位和一周的时间范围进行过滤,加载所有这些事件也可能会使服务器过载,无法提供流畅的用户体验。
最后两个函数为我们的mapManager添加了一些非常重要的功能。
//takes an event and adds it as a marker to the map
public addEventToMap(eventJson) {
var eventId = eventJson.Id;
var longitude = eventJson.Longitude;
var latitude = eventJson.Latitude;
var eventName = eventJson.Name;
//create a google LatLng representation
var eventLatLong = new google.maps.LatLng(latitude,longitude);
//create the marker containing the LatLng & the name of the event
var marker = new google.maps.Marker({
position: eventLatLong,
title: eventName
});
//add to local instance, so it can be cleared later
this._markerArray.push(marker);
//add to the map
marker.setMap(this._map);
}
//clears all events from the map
public clearEvents() {
//iterate current markers and remove from map
$.each(this._markerArray, (index, marker) => {
marker.setMap(null);
});
//clear the array
this._markerArray = [];
}
addEventToMap函数接受一个json事件作为参数,根据其中包含的地理坐标创建一个google.map.Marker对象,并将其添加到我们的地图中。clearEvents函数在每次ajax请求之前被调用,以避免重复添加事件。
最终,这将呈现出我们美观的Google地图,其中填充了我们导入的所有有趣活动。

当然,认识一些出色的网站设计师也非常有用,经过一些令人印象深刻的CSS/HTML样式和一些调整后,我们就得到了最终的解决方案!

这在台式机上效果很好,但我们还没有完成!
走向移动端
随着能够访问互联网的设备类型和尺寸呈指数级增长,CityPulse面临着又一个挑战。我们需要为每个人提供引人入胜、无缝且愉快的体验,无论他们身在何处,使用何种设备——从屏幕较小、漫游连接不稳定的老式手机到超高速宽带42英寸高清电视屏幕。幸运的是,有一种绝佳的方法可以实现这一点,而无需为各种原生平台开发和维护多个代码库——我们可以通过响应式设计来实现。
那么,什么是响应式设计?
简而言之,响应式设计允许我们使用具有流畅布局的单个网站,该布局会根据屏幕尺寸进行自适应,我们可以通过利用HTML5和CSS3媒体查询来定位特定屏幕尺寸的不同CSS样式来实现这一点。如果您是响应式设计的新手,Shay Howe有一个很棒的教程,可以简洁地涵盖所有内容。
就这么简单吗?
是的,也不是。响应式设计将帮助我们优化每种设备尺寸的观看体验,但对于触摸屏设备、连接速度慢或用户在不同设备上的不同期望又如何呢?我们需要引入一些不同的技术和策略来涵盖所有内容。让我解释一下我们如何让CityPulse适应各种场景,逐点说明。
1. 不同尺寸屏幕的设备
2. 触摸屏设备
3. 可变/间歇性带宽
4. 不同的用户旅程/期望
1. 不同尺寸屏幕的设备
响应式设计解决了在现实环境中应用程序可能遇到的多种屏幕尺寸和像素比问题。布局使用流动的百分比宽度和高度创建,这些宽度和高度会随着不同尺寸的屏幕而扩展和收缩(您可以访问CityPulsel并调整浏览器大小来尝试!)。文本也会相应调整大小以保持可读性,并且某些图片有不同的尺寸,因此手机不必加载任何巨大的图片。即使我们的布局在屏幕调整大小时保持流动,但设计也会在某些尺寸下出现问题(称为“断点”),这时我们就需要用CSS3媒体查询来干预。
在我们开始处理断点之前,需要说明一点:CSS媒体查询在Internet Explorer 8及更低版本中不受支持,因此我们还将使用JavaScript插件“css3-mediaqueries”来保持跨浏览器支持。这只会在IE版本低于9时加载,方法是在html的
标签中使用以下代码。!--[if lt IE 9]> <script src="/css3-mediaqueries.js"></script> <![endif]-->
该插件由Manish Salunke创建,可以在他的网站cssmatters上找到。它通过将CSS媒体查询转换为IE可以识别的JavaScript来巧妙地完成所有工作。
断点
我们有三个主要的宽度断点:小于764px,小于1024px,以及大于1024px。最佳实践是根据设计而不是常见的设备尺寸来确定设计的断点,但巧合的是,这个特定设计的断点非常接近手机、平板电脑和宽屏的主要设备组(只需稍作调整!)。我们实施的更改是经过深思熟虑的,以免影响整体用户体验,但足以适应可用空间和布局的变化。我们还有一些次要断点:宽度大于1200px,大于1650px(极宽),高度小于360px和500px。
因此,为了详细说明我们的设计如何适应这些主要断点,我将展示一张按设备尺寸划分的主要响应式设计布局图,然后在下方提供详细的代码示例。

A.最具挑战性的断点是屏幕宽度小于764px(大约是手机或小型平板电脑尺寸)。在此尺寸下,没有足够的可用空间使信息面板和地图并排放置,因此它们都变成全宽视图,通过屏幕两侧的按钮交替访问。侧边导航和顶部过滤器压缩为弹出菜单,以便在不需要时腾出宝贵的空间。此外,还根据人们与手机的交互方式做出了一些设计决策,这些将在“不同的用户旅程/期望”部分进行介绍。
CityPulse的所有样式都是使用LESS创建的,LESS是CSS的扩展,为CSS增加了新功能和动态行为。您可以在LESS网站上阅读更多内容。这是我们用来开始媒体查询的第一行LESS/CSS。
@media all and (max-width: 764px){
第一行声明这些样式适用于所有媒体类型(屏幕、打印等),并指定了最大宽度。所有未包含在这些样式中的非媒体查询样式仍然适用,但任何定位相同元素的样式都将被覆盖,除非它们包含!important或更具体(参见Smashing Magazine关于CSS特异性的文章)。
以下是我们在此媒体查询中应用于设计的一些主要样式:
.map-button {
display:block;
position:absolute;
bottom:0;
right:0;
z-index:250;
}
此地图按钮在主样式中设置为'display:none;',仅在屏幕宽度小于764px时通过将其属性设置为“block”而变得可见。 由于在此宽度下无法同时显示地图和事件列表,因此该按钮允许用户通过使用JavaScript函数使地图滑动来切换它们。
#smalldevice-intro {
display: block;
text-align: center;
h5 {
max-width:70%;
margin: 0 auto;
color:@accentcolor3;
font-weight:normal;
text-shadow:1px 1px 1px #000;
}
}
在此小尺寸下,我们不显示加载全局顶事件的标准启动屏幕,因此为了让用户不遗漏我们的标语,我们将其包含在他们看到的第一屏中。它像地图按钮一样被隐藏(使用display设置),然后在此特定尺寸下设置为可见。
#sidemenu-tablet-refine-search {
display: block;
}
#header-right.tabletmenuopen {
//when menu is active change refine button colour
#tablet-refine-search.button-type2 {
background: url(/Images/dark-texture.png) repeat #212121;
}
}
#arrow-left-close {
display: none;
}
#header-left {
height: 40px;
background: none;
width: 100%;
.site-title {
display: none;
}
}
#tablet-refine-search {
display: none;
}
#sidenavbar-wrapper {
width: 100%;
}
.sidemenu-scrollinner {
margin-top: 110px;
}
// hide rhs header - but raise z-index for menu button
#header-right {
width: 100%;
z-index: 200;
height: 0px;
.whatsonselect {
z-index: 200;
margin-top: 0px;
background: url(/Images/dark-texture.png) repeat #212121;
.whatsonlocation {
top: 60%;
}
#clickmenu-date {
top: 30%;
padding:3px 0;
}
#clickmenu-category {
top: 45%;
padding:3px 0;
}
}
}
.whatsonselect-choose {
.BOX-SHADOW(0, 0, 5px, 0, 0.7) !important;
}
此代码片段执行几项操作:它将我们的侧面板宽度设置为占据整个屏幕,它显示一个新按钮,该按钮可在侧边导航条中切换过滤器视图和列表视图,并整齐地排列过滤器下拉菜单,使其与容器顶部保持合理的距离。
以下屏幕截图演示了屏幕尺寸变化的影响。

B.对于屏幕宽度在764到1024px之间(大约是标准平板电脑或小型显示器尺寸)的设备,侧面板和地图现在都被样式化为屏幕宽度的50%。这是为了保持侧面板文本的每行单词数量最适宜,以获得清晰的可读性。我们还将过滤器菜单压缩为一个“Refine”按钮,而不是像在更宽的设备/屏幕上那样分散过滤器。当宽度变得太小时,过滤器按钮会开始超出其容器;当高度变得太小时,过滤器下拉菜单会从屏幕底部消失。因此,它们被安排在自己的面板中,并带有滚动条,如果屏幕高度不足以容纳内容,则通过将overflow设置为“auto”来显示这些滚动条。
@media (min-width: 765px) and (max-width:1024px), (max-height:500px) {
媒体查询声明适用于大于765px但小于1024px的屏幕尺寸,以及高度小于500px的屏幕尺寸。
#tablet-refine-search {
display: block;
position: absolute;
top: 10px;
right: 20px;
padding: 10px;
cursor: pointer;
}
#header-left {
width: 50%;
}
#sidenavbar-wrapper {
width: 50%;
}
#whatsonsearch {
display: none;
}
#header-right {
width: 50%;
}
}
LESS/CSS的这些行将侧面板的宽度设置为50%,这在容器“#header-left”和“#sidenavbar-wrapper”内。 它还显示了一个新按钮,该按钮对更大和更小的屏幕尺寸是隐藏的,该按钮通过从左侧滑动来切换过滤器菜单。
.whatsonlocation {
width: 80%;
position: absolute;
top: 50%;
right: 20%;
display: block;
}
#clickmenu-date {
width: 80%;
position: absolute;
top: 10%;
right: 20%;
}
#clickmenu-category {
width: 80%;
position: absolute;
top: 30%;
right: 20%;
}
#whatsonsearch {
width: 100%;
display: block;
position: absolute;
bottom: 0;
background: url(/Images/dark-texture.png) repeat #212121;
button {
width: 60%;
margin: 10px auto;
// float: right;
padding: 0 5px;
.button-type2;
color: @accentcolor3;
text-shadow: none;
&:hover {
.SELECTEDMENU;
}
}
}
这将为过滤器按钮提供一种新的布局,适合菜单新的50%宽度。对于ID为“whatsonsearch”的按钮,该按钮通常显示在屏幕右上方,是一个黑色的“GO”按钮,我们给它一个更醒目的背景容器,更亮的蓝色,并将按钮元素样式化得更大,以便在触摸屏设备上更容易/更准确地按下。

C.对于宽度大于1024px的设备,我们的内容现在有空间展开。对于较小尺寸位于滑动面板内的过滤器,现在始终显示在标题的右上方。当点击这些过滤器中的任何一个时,它的菜单会弹出显示在地图上方。侧面板的宽度现在被样式化为35%,因此随着额外空间的增加,地图和标记在设计中可以占据更重要的位置。
此屏幕尺寸的所有样式都不包含在媒体查询中,因为它们被设置为通用网站样式。 为了不将所有样式包含在这篇文章中(其中有很多!),我只会包含一些设置我们已讨论的此尺寸主要布局的片段。
#header-left {
position: absolute;
top: 0;
left: 0;
width: 35%;
height: 60px;
background: url('/images/header-lbg.png') repeat-x #313131;
z-index: 120;
}
#header-right {
width: 65%;
height: 60px;
background: url('/images/header-lbg.png') repeat-x #313131;
position: absolute;
top: 0;
right: 0;
height: 60px;
z-index: 110;
}
.whatsonselect {
float: right;
width: 92%;
padding: 0;
margin: 0;
.whatsonlocation {
float: left;
width: 31%;
max-width: 550px;
min-width: 175px;
color: @accentcolor3;
line-height: 16px;
margin-top: 10px;
height: 35px;
font-size: 14px;
cursor: pointer;
position: relative;
border-radius: 0 6px 6px 0;
text-align:right;
}
#whatson-icon-location {
position: absolute;
top: 0px;
right: 0px;
border-radius: 0 5px 5px 0;
}
在这里,我们将侧面板和左侧标头宽度设置为35%。右侧标头的大小设置为65%,与地图的宽度匹配。在右侧标头内部,过滤器按钮位于其容器设置为65%右标头包装器宽度的92%处。 我们还将每个过滤器按钮的宽度设置为大约为其容器宽度的三分之一,还设置了每个按钮的最大和最小宽度以防止其布局中断。

2. 触摸屏设备
触摸屏设备带来了一些鼠标无法完成的功能,例如“悬停”,但它带来了一整套新的手势,如捏、滑动等。为了优化触摸屏设备,我们首先使用插件“Modenizr”来检测设备是否支持触摸。然后,我们根据此结果决定运行哪些样式表和JavaScript函数,相对于是否对触摸友好。如果我们发现设备支持触摸,我们还会加载插件“TouchSwipe”,它允许我们利用许多触摸屏手势,例如在手机上使用“滑动”手势在地图和列表视图之间滑动。
因此,要检测设备是否支持触摸,我们运行以下脚本:
if ( Modernizr.touch ) {
...
}
在此if语句中,我们加载了启用滑动地图的插件。使用此方法的一个缺点是,某些版本浏览器和某些设备的触摸屏功能可能无法正确响应,因此,作为一种备用方案,我们还提供了地图按钮的单击功能。
3. 可变/间歇性带宽
当从手机访问网站时,我们假设连接速度会比其他设备慢,并采取几种不同的措施进行优化。过滤器菜单是用户看到的第一个屏幕,然后才能加载地图及其所有数据。这很棒,因为它允许用户选择他们的位置、日期和活动类型,因此只会调用符合他们要求的活动,让使用3G连接且数据流量有限的用户满意。

我们为小型设备降低服务器请求数据量的另一种方式是降低地图上显示的顶级事件标记的数量。这在视觉上也很有意义,较小的地图显示标记的表面积较小,因此我们的宽屏显示器每视图显示约100个顶级事件标记,而手机将显示30个。
对于那些可能会遇到互联网连接中断的“随时随地”的用户,我们利用内存缓存来确保先前加载的事件仍然可以暂时访问。
4. 不同的用户旅程/期望
在设计和编码网站以适应不同类型的设备和不同尺寸的屏幕时,也考虑了用户可能希望与站点交互的不同方式。
我们的移动设备用户可能正在“ unterwegs ”寻找附近的、正在发生的活动。因此,我们的筛选菜单也兼具“快速选择器”和带宽保护器的作用。使用笔记本电脑和台式机的用户可能在家或工作时访问该网站,也许会提前寻找活动。这些用户将体验到不同的界面,显眼的地图将是他们首先看到的东西,而热门活动则列在旁边,这鼓励他们探索身边的活动。筛选器对这些用户来说也很明显,位于标头内,但我们预设了日期,以便这些用户可以显示本周的所有活动。
结论
好了,就是这样!我们创建了一个功能齐全的网站,只需单击一下即可在全球范围内提供 Facebook 活动。
Azure 中的自动导入流程使事件数据库保持最新,网站通过运行单页应用程序提供流畅的用户体验,响应式设计使用户能够真正无障碍地访问,无论他们使用何种设备。
但不要只听我们说,自己去网站逛逛吧——你甚至可能会发现这个周末你有什么活动!

历史
13/06/08 - 添加了“想法”、“架构”、“技术”和“导入流程”的草稿
13/06/09 - 添加了“使用 Azure 虚拟机导入流程;工作节点 A、B 和 C”的草稿
13/06/16 - Beta 网站上线
13/06/17 - 添加了“存储”的草稿,添加了“网站”的草稿。
13/06/23 - 添加了“移动化”,完成了“网站”,并进行了一些其他更新